DAGScheduler源码分析,
DAGScheduler 实现详解
以RDD的Action count为例。
RDD的count实际是调用sparkContext的org.apache.spark.sparkContext#runjob来进行提交job
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
SparkContext实现了很多runjob,p这些函数的区别,就是参数的不同,这些runjob最后都会调用DAGScheduler的runjob
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, allowLocal, resultHandler, localProperties.get)
1.1 DAGScheduler的创建
TaskScheduler和DAGScheduler都是在SparkContext创建的时候创建的。两者创建的方式不同:
- TaskScheduler是SparkContext通过SparkContext下的createTaskScheduler创建的
- DAGScheduler是直接调用它的构造函数创建的
package org.apache.spark.SparkContext
// SparkContext在创建DAGScheduler
dagScheduler = new DAGScheduler(this)
package org.apache.spark.scheduler.DAGScheduler
// 这个构造函数实现的实现
def this(sc: SparkContext) = this(sc, sc.taskScheduler)
// this(sc, sc.taskScheduler)的实现
def this(sc: SparkContext, taskScheduler: TaskScheduler) = {
this(
sc,
taskScheduler,
sc.listenerBus,
sc.env.mapOutputTracker.asInstanceOf[MapOutputTrackerMaster],
sc.env.blockManager.master,
sc.env)
}
// this(sc, sc.taskScheduler)的实现通过调用下面构造函数完成DAGScheduler的创建
private[spark]
class DAGScheduler(
private[scheduler] val sc: SparkContext,
private[scheduler] val taskScheduler: TaskScheduler,
listenerBus: LiveListenerBus,
// 是运行在Driver端管理Shuffle Map Task的输出的
// 下游的Task可以通过MapOutputTrackerMaster来获取Shuffle输出的位置信息
mapOutputTracker: MapOutputTrackerMaster,
// 管理整个Job的Block信息
blockManagerMaster: BlockManagerMaster,
env: SparkEnv,
clock: Clock = new SystemClock())
extends Logging {}
在Spark 1.0版本之前,在DAGScheduler类中加入eventQueue私有成员,设置eventLoop Thread循环读取事件进行处理。
在Spark 1.0源码中,事件处理通过Actor的方式进行,涉及的DAGEventProcessActor类进行主要的事件处理工作。
在Spark 1.3源码中,DAGScheduler重新采用eventQueue的方式进行事件处理,为了代码逻辑更加清晰,耦合性更小,添加了DAGSchedulerEventProcessLoop类进行事件处理。
package org.apache.spark.scheduler.DAGScheduler
def taskStarted(task: Task[_], taskInfo: TaskInfo) {
// 底层调用的是 eventQueue.put(event)
eventProcessLoop.post(BeginEvent(task, taskInfo))
}
private[scheduler] class DAGSchedulerEventProcessLoop(dagScheduler: DAGScheduler)
extends EventLoop[DAGSchedulerEvent]("dag-scheduler-event-loop") with Logging {
event match ....
}
这里DAGSchedulerEventProcessLoop继承了EventLoop类
package org.apache.spark.util.EventLoop
private[spark] abstract class EventLoop[E](name: String) extends Logging {
private val eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]()
private val stopped = new AtomicBoolean(false)
private val eventThread = new Thread(name) {
// 设置线程等待
setDaemon(true)
override def run(): Unit = {
try {
// 循环获取队列中内容
while (!stopped.get) {
val event = eventQueue.take()
try {
// 事件轮询时,调用事件线程
onReceive(event)
}
.....
def start(): Unit = { // 创建event处理线程
if (stopped.get) {
throw new IllegalStateException(name + " has already been stopped")
}
onStart()
eventThread.start()
}
通过上述问题不难发现:DAGScheduler通过向DAGSchedulerEventProcessLoop对象投递event,即向eventQueue发送event,eventThread不断从eventQueue中获取event并调用onReceive函数进行处理。
package org.apache.spark.scheduler.DAGScheduler# DAGSchedulerEventProcessLoop
override def onReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, allowLocal, callSite, listener, properties)
.......
1.2 Job提交
用户提交最终会调用DAGScheduler的runjob,它又会调用submitJob。
以RDD Count为例,调用过程如下
org.apache.spark.rdd.RDD.RDD#countorg.apache.spark.rdd.SparkContext#runJoborg.apache.spark.scheduler.DAGScheduler#runJoborg.apache.spark.scheduler.DAGScheduler#submitJoborg.apache.spark.scheduler.DAGSchedulerEventProcessLoop#onReceiveorg.apache.spark.scheduler.DAGScheduler#handleJobSubmitted
调用栈3主要实现就是调用submitJob调用:
//submitJob就是我们job执行的关键方法
val waiter = submitJob(rdd, func, partitions, callSite, allowLocal, resultHandler, properties)
SubmitJob会首先为这个Job生成一个JobID, 并且生成一个JobWaiter的实例来监听Job情况
//获取所有的分区
val maxPartitions = rdd.partitions.length
//判断所有的分区都是可用的
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
//创建一个新的JobID
//jobId是以自增的形式创建的
val jobId = nextJobId.getAndIncrement()
if (partitions.size == 0) {
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.size > 0)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
// 将JobSubmitted对象添加到队列中
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, allowLocal, callSite, waiter, properties))
waiter
Jobwaiter会监听Job执行状态,由于Job是由多个Task组成的,因为Job所有的Task都成功完成,Job才会被标记成功;如果不成功则会通过调用org.apache.spark.scheduler.JobWaiter#jobFailed.
会将JobSubmitted对象放入队列中。 循环取出队列中的事件,调用org.apache.spark.scheduler.DAGSchedulerEventProcessLoop#onReceive调用,最终会调用org.apache.spark.scheduler.DAGScheduler#handleJobSubmitted 提交这次的Job
override def onReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, allowLocal, callSite, listener, properties) =>
// dagScheduler.handleJobSubmitted
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, allowLocal, callSite,
listener, properties)
......
1.3 Stage划分
package org.apache.spark.scheduler.DAGScheduler#handleJobSubmitted
//此处就开始进行Stage划分操作
finalStage = newStage(finalRDD, partitions.size, None, jobId, callSite)
// 创建activeJob提交任务
val job = new ActiveJob(jobId, finalStage, func, partitions, callSite, listener, properties)
首先会根据RDD创建finalStage–最后的那个Stage。然后创建active后提交任务。
什么是Stage?
- 用户提交的计算任务是由RDD构成的DAG,如果DAG转换时需要做Shuffle,那么这个Shuffle过程就将就将这个DAG分为了不同的阶段。这个阶段就叫Stage
- 由于Shuffle的存在,后面的Stage的计算需要Stage的Shuffle结果,所以不同的Stage是不能并行的
- 一个Stage由一组完全独立的Task(计算任务)组成,每个Task的区别,只是处理各自对应的Parition,一个Partition会被该Stage中的一个Task处理
划分依据
- 对于窄依赖
- RDD的每个Partition依赖固定数据量的parent RDD的Partition,因此可以通过一个Task来处理这些Partition,而且这些Partition是相互独立的,所以这些Task可以并行。
- 对于宽依赖
- 它是需要Shuffle的,只有所有parent RDD的Parition Shuffle完成,新的Parition才会形成,接下来的Task才可以处理。因此,宽依赖是DAGr的分界线,Spark根据宽依赖将Job划分成不同的Stage
划分过程
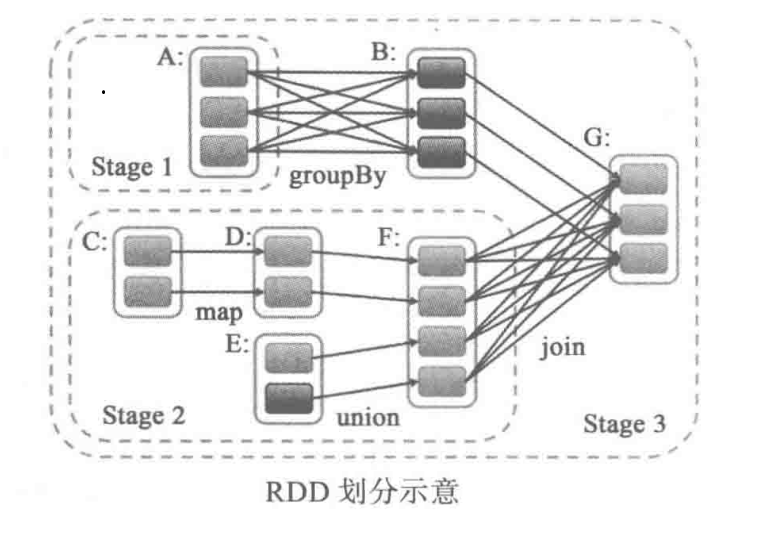
Stage的划分是从RDD G开始的,也就是触发Action的那个RDD。首先RDD G 会从SparkContext的runJob开始通过以下的调用栈来开始Stage划分:
org.apache.spark.SparkContext#runJoborg.apache.spark.scheduler.DAGScheduler#runJoborg.apache.spark.scheduler.DAGScheduler#submitJoborg.apache.spark.scheduler.DAGSchedulerEventProcessLoop#onReceive(JobSubmitted)org.apache.spark.scheduler.DAGScheduler#handleJobSubmitted
handleJobSubmitted会开始Stage的划分。
实现细节
handleJobSubmitted通过调用org.apache.spark.scheduler.DAGScheduler#newStage创建finalStage,即上图中的Stage 3
package org.apache.spark.scheduler.DAGScheduler#handleJobSubmitted
//此处就开始进行Stage划分操作
finalStage = newStage(finalRDD, partitions.size, None, jobId, callSite)
newStage首先会获取当前Stage的parent Stage,然后创建当前Stage
//获取最终RDD的所有父RDD
val parentStages = getParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
//将所依赖的Stage存放到最终的RDDstage上
val stage = new Stage(id, rdd, numTasks, shuffleDep, parentStages, jobId, callSite)
通过调用getParentStages,图中的Stage 1 和 Stage 2 就创建出来了。然后根据他们创建Stage 3。
getParentStages是划分的核心方法。它负责生成当前RDD所在stage的parent Stage
private def getParentStages(rdd: RDD[_], jobId: Int): List[Stage] = {
val parents = new HashSet[Stage] //存储parent Stage
val visited = new HashSet[RDD[_]] //创建一个HashSet,用于记录已遍历过的RDD
// 存储需要被处理的RDD,Stack中的RDD需要被处理
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) { // 广度优先遍历RDD生成的依赖树
if (!visited(r)) {
visited += r
//RDD的类型分类MapPartitionRDD和ShuffledRDD
for (dep <- r.dependencies) { //逐个处理当前RDD依赖的parent RDD
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
//只要依赖是ShuffleDependendy类型时,生成新的Stage
parents += getShuffleMapStage(shufDep, jobId)
case _ =>
//此处就是说,当前RDD所依赖的RDD为非ShuffleRDD,那么就属于同一个stage
waitingForVisit.push(dep.rdd)
}
}
}
}
// 以输入的rdd作为第一个需要处理的RDD。然后,从该RDD开始,顺序处理其parent rdd
waitingForVisit.push(rdd)
while (!waitingForVisit.isEmpty) { //只要stack不为空则一直处理
// 每次visit如果是ShuffleDependency, 那么就会形成一个Stage,
// 否则这些RDD属于同一个stage
visit(waitingForVisit.pop())
}
//也就是说,parents中存放的是多个ShuffleMapRDD所转化的Stage对象
parents.toList
}
getShuffleMapStage 获取ShuffleDependency所依赖的Stage,如果没有则创建新的Stage:
package org.apache.spark.scheduler.DAGScheduler#getShuffleMapStage
private def getShuffleMapStage(shuffleDep: ShuffleDependency[_, _, _], jobId: Int): Stage = {
shuffleToMapStage.get(shuffleDep.shuffleId) match { //根据shuffleID查找Stage是否存在
case Some(stage) => stage // 如果已经创建,则直接返回
case None =>
// 看该Stage的parent stage是否生成,没有,则生成parent Stage
registerShuffleDependencies(shuffleDep, jobId)
// 生成当前rdd所在stage
val stage =
// 生成一个stage,如果存在,将恢复这个stage的结果
newOrUsedStage(
shuffleDep.rdd, shuffleDep.rdd.partitions.size, shuffleDep, jobId,
shuffleDep.rdd.creationSite)
shuffleToMapStage(shuffleDep.shuffleId) = stage
stage
}
}
上述代码中有两个核心代码:
registerShuffleDependencies负责确认该Stage的parent Stage是已经生成,如果没有则生成它们newOrUsedStage负责生成一个Stage,如果该Stage已经存在,那么将恢复这个Stage。避免重复计算
registerShuffleDependencies的源码如下
private def registerShuffleDependencies(shuffleDep: ShuffleDependency[_, _, _], jobId: Int) = {
// 获取没有生成Stage的shuffleDependency, 它会判断Shuffle依赖是否存在
val parentsWithNoMapStage = getAncestorShuffleDependencies(shuffleDep.rdd)
while (!parentsWithNoMapStage.isEmpty) {
val currentShufDep = parentsWithNoMapStage.pop()
// 根据shuffleDependency来生成stage
val stage =
newOrUsedStage(
currentShufDep.rdd, currentShufDep.rdd.partitions.size, currentShufDep, jobId,
currentShufDep.rdd.creationSite)
shuffleToMapStage(currentShufDep.shuffleId) = stage
}
}
getAncestorShuffleDependencies 的实现与getParentStages类似,但是它遇到ShuffleDependency时会首先判断Stage是否已经存在,不存在时把这个依赖作为返回值的一个元素,由调用着完成Stage创建。
newOrUsedStage的实现如下
val stage = newStage(rdd, numTasks, Some(shuffleDep), jobId, callSite)
if (mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
// Stage已经被计算过,从mapOutputTracker中获取计算结果
val serLocs = mapOutputTracker.getSerializedMapOutputStatuses(shuffleDep.shuffleId)
val locs = MapOutputTracker.deserializeMapStatuses(serLocs)
for (i <- 0 until locs.size) {
// 计算结果复制到Stage中
stage.outputLocs(i) = Option(locs(i)).toList //locs(i) will be null if missing
}
// 保存Stage可用结果的数量;对于不可用的部分,会被重新计算
stage.numAvailableOutputs = locs.count(_ != null)
} else {
// 向mapOutputTracker注册该Stage
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.size)
}
1.4 任务生成
handleJobSubmitted创建finalStage后,就会为该Job创建一个org.apache.spark.scheduler.ActiveJob,并准备计算这个finalStage
package org.apache.spark.scheduler.DAGScheduler#handleJobSubmitted
val job = new ActiveJob(jobId, finalStage, func, partitions, callSite, listener, properties)
如果这个任务满足以下所有条件,那么它会以本地模式运行:
spark.localExecution.enable设置为ture- 用户程序指定为本地运行
- finalStage 没有 Parent Stage
- 仅有一个Partition
其中,3和4主要是为了保证任务可以快速执行;如果有多个Stage和多个Partition,本地运行可能会因为计算机资源的局限性而影响任务的计算速度。
排除本地运行的,handleJobSubmitted会调用 submitStage提交这个Stage。如果它的某些parent Stage没有提交,那么递归提交那些未提交的parent Stage。只有parent Stage都计算完成后,才能够提交它
submitStage源码
package org.apache.spark.scheduler.DAGScheduler #submitStage
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
// 如果当前stage不在等待其parent Stage返回,不是正在运行,且没有失败,那么就尝提交它
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing == Nil) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
// 有parent stage未完成则递归提交它
submitStage(parent)
}
waitingStages += stage
}
}
} else { //无效的Stage, 直接停止
abortStage(stage, "No active job for stage " + stage.id)
}
}
前面图的Stage提交逻辑图如下图所示。
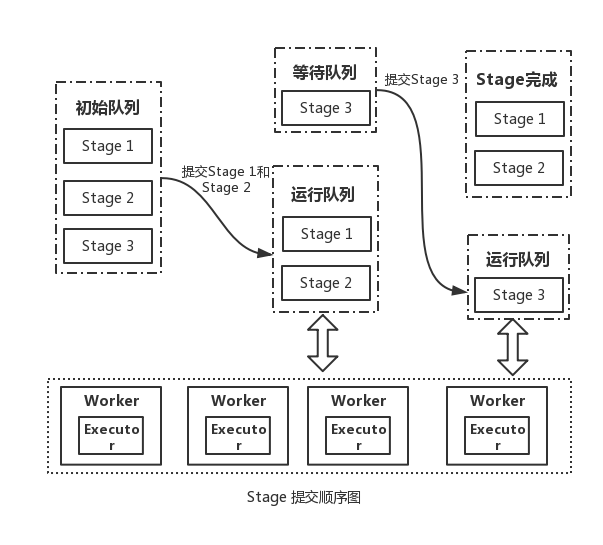
三个Stage中, Stage1 和Stage2是可以并行的,因此在有计算机资源的情况下会首先被提交,并且在两个Stage计算都成功完成的情况下,提交Stage3。最后的计算都是在计算结点的Execor中执行的。
org.apache.spark.scheduler.DAGScheduler#submitMissingTasks会完成DAGScheduler最后的工作,向TaskScheduler提交Task。
getMissingParentStages核心源码:
package org.apache.spark.scheduler.DAGScheduler#getMissingParentStages
// 首先获取需要计算的Partition 下标(id)
val partitionsToCompute: Seq[Int] = {
if (stage.isShuffleMap) {
(0 until stage.numPartitions).filter(id => stage.outputLocs(id) == Nil)
} else {
val job = stage.resultOfJob.
get(0 until job.numPartitions).filter(id => !job.finished(id))
}
}
val taskBinaryBytes: Array[Byte] =
if (stage.isShuffleMap) {
//此处会将RDD的对象进行序列化,默认使用Java的对象序列化算法
closureSerializer.serialize((stage.rdd, stage.shuffleDep.get) : AnyRef).array()
} else {
closureSerializer.
serialize((stage.rdd, stage.resultOfJob.get.func) : AnyRef).array()
}
// 将任务放置广播变量中
taskBinary = sc.broadcast(taskBinaryBytes)
// 为每个Partition生成Task
val tasks: Seq[Task[_]] =
// 如果是最后一个Stage,它对应的是ResultTask,其它的则是ShuffleMapTask
if (stage.isShuffleMap) {
//关于task计算的位置选择
partitionsToCompute.map { id =>
val locs = getPreferredLocs(stage.rdd, id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, taskBinary, part, locs)
}
} else {
val job = stage.resultOfJob.get
partitionsToCompute.map { id =>
val p: Int = job.partitions(id)
val part = stage.rdd.partitions(p)
val locs = getPreferredLocs(stage.rdd, p)
//collect、count
new ResultTask(stage.id, taskBinary, part, locs, id)
}
if (tasks.size > 0) {
stage.pendingTasks ++= tasks
// 将Tasks封装到TaskSet中,然后提交给TaskScheduler
taskScheduler.submitTasks(
new TaskSet(tasks.toArray, stage.id, stage.newAttemptId(), stage.jobId, properties))
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
} else {
// 没有任务,标记Stage为已完成
markStageAsFinished(stage, None)
}
从逻辑上来看Stage包含TaskSet:
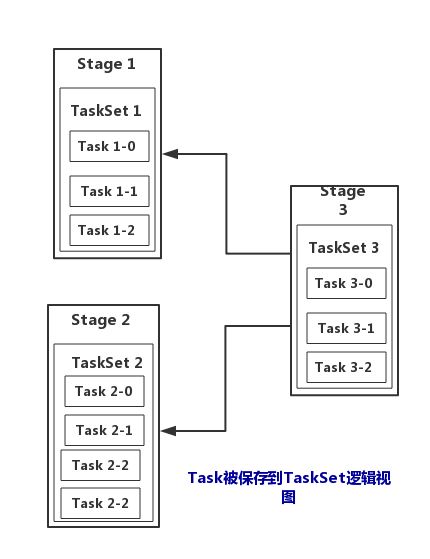
TaskSet保存了Stage包含的一组完全相同的Task,每个Task的处理逻辑完全相同,不同的是处理的数据,每个Task负责处理一个Partition。对一个Task,它数据源获得逻辑,然后按拓扑顺序,顺序执行。
DAGScheduler就完成了它的使用,然后它会等待TaskScheduler最终向集群提交这些Task,监听这些Task状态。
参考:

