scheduler模块概述, spark源码版本1.3
Scheduler模块详解
Scheduler(任务调用)是Spark Core核心之一,充分体现了与Mapreduce完全不同的设计思想。
那么它们之前的任务,是怎么进行调度的,组成应用的Job是如何分配资源的呢。
1 模块概述
1.1 整体架构
任务高度分为两大模块: DAGScheduler和TaskScheduler。它们负责将用户提前的计算任务按照DAG划分为不同的阶段并且将不同阶段的计算任务提交到集群进行最终计算。
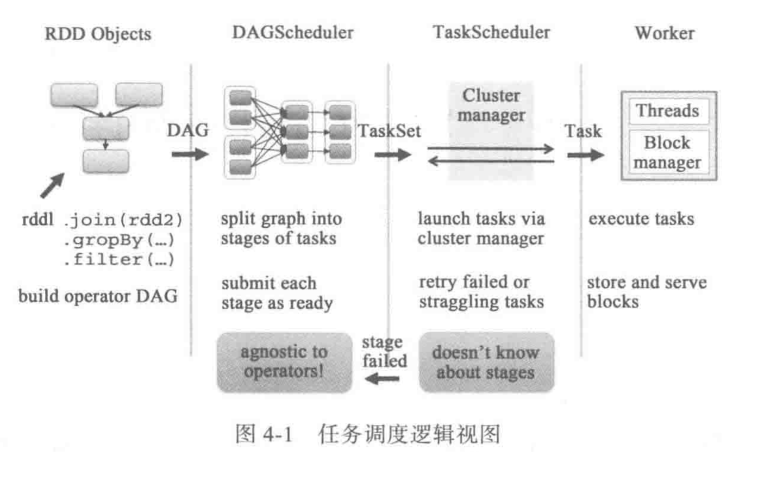
RDD Object用户实际代码中创建的RDD。DAGScheduler负责分析用户提交的应用,并根据计算任务的依赖建立DAG,然后将DAG划分成不同的Stage,其中每个Stage由可以并发执行一组Task构成,这些Task的执行逻辑完全相同,只是执行的数据不同。DAGScheduler将这组Task划分完成之后 ,会将这组Task提交到TaskScheudler。TaskScheduler通过Cluster Manager在集群中的某个Worker的Executor上启动任务。- 在
Executor中运算的任务,如果缓存中没有计算结果,则需要开始计算,同时,计算的结果会回传到Driver或保存到本地。
1.2 Scheduler的实现概述
任务调用三个主要的模块:
org.apache.spark.scheduler.DAGScheduler- DAGScheduler的实现
org.apache.spark.scheduler.SchedulerBackend- 是一个trait, 主要作用是分配当前资源。
- 具体来说,向当前等待资源的Task分配计算资源(即 Executor),并且在分配的Executor上启动Task,完成计算的调度过程。它最重要的实现是
reviveOffers
org.apache.spark.scheduler.TaskScheduler- 是一个trait, 主要作用是创建SparkContext调度任务。
- 从DAGScheduler接收不同Stage任务,并且向集群提交任务,并为执行特别慢的任务启动备份任务
org.apache.spark.scheduler.TaskSchedulerImpl是其唯一实现
TaskSchedulerImpl会在以下几种场景下调用org.apache.spark.scheduler.SchedulerBackend# reviveOffers:
- 有新任务提交
- 有任务执行失败
- 计算节点(即Executor)不可用时
- 某些任务执行过慢而需要为它重新分配资源时
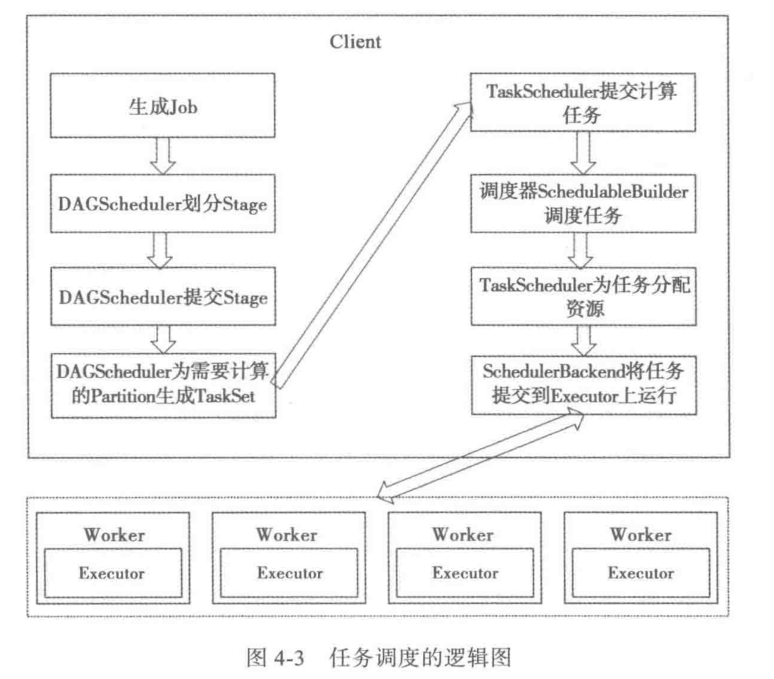
任务调度逻辑图:
参考:

