SparkStreaming基础及操作
SparkStreaming
1 架构图

-
Spark Streaming 是Spark Core核心API的扩展,高吞吐量、实时处理、容错机制的实时数据流。
-
支持多种数据来源方式,如Kafka、TCP Socket、Flume等
-
经过处理的数据,可以存储在数据库或HDFS或图表上
Spark Streaming的工作原理如下。接受实时的数据流,并且将数据分批,然后由Spark引擎处理,最后生成批量生成最终的结果流。
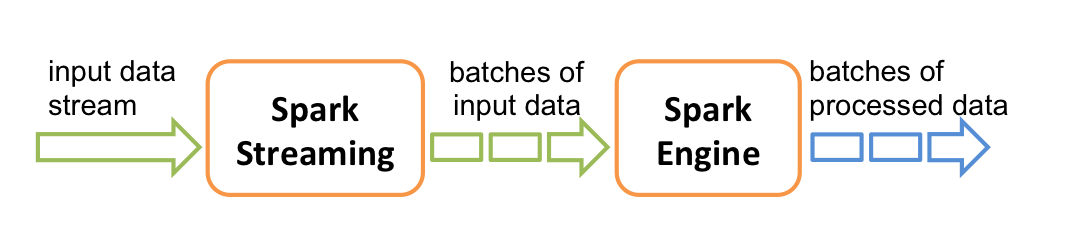
Spark提供一个高级抽象,称之为discretized stream or DStream,它代表连续的数据集。
流式计算的特点:
- 数据源源不断进行传输。
实时计算特点:
- 每次传输的数据量,比离线的数据量小得的多
- 传输的次数多
实时计算的应用场景:
- 低延迟
- 源源不源
2 wordCount程序
wordCount程序操作
// linux上预备环境 yum -y install nc
// nc -lk 9999 启动9999端口
// local 至少要填2,一个线程监听 一个线程做计算
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
3 Discretized Streams (DStreams)
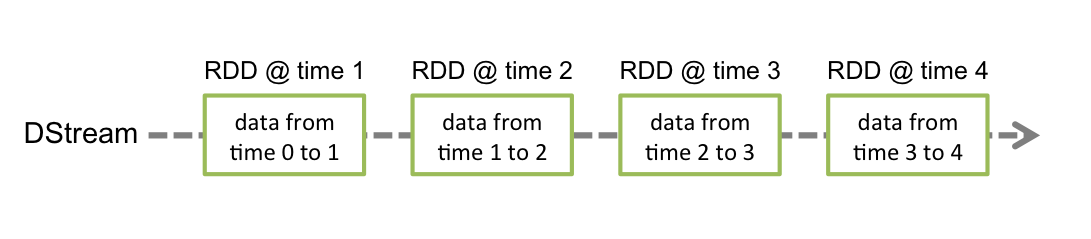
- 它表示源源不断的数据
- DStream由一串连续的RDD表示
- DStream中的RDD都包含来个某个时间段的数据
DStream的操作,在底层都将转化成RDD操作。
3. 1 UpdateStageByKey
如果要使用UpdateStageByKey函数,需要在执行该操作前,进行Checkpoint操作
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = newValues.sum + runningCount.getOrElse(0)
Some(newCount)
}
这通常用在WordCount中,reducebyKey的前面
val runningCounts = pairs.updateStateByKey[Int](updateFunction _)
3.2 Transform Operation
需求: 淘宝黑名单过滤
val ssc = new StreamingContext(conf, Seconds(5))
val blackList = Array("zc", "ls", "ww", "此去经年", "猪头少年").map((_, 0))
val blackListRDD = ssc.sparkContext.parallelize(blackList)
// 输入的格式为 1001, zc
val lines = ssc.socketTextStream("hadoop1", 9999, StorageLevel.MEMORY_ONLY)
lines.print()
lines
.map(x => ( x.split(",")(1), x.split(",")(0)))
.transform( rdd => {
rdd.leftOuterJoin(blackListRDD)
.filter(_._2._2.getOrElse(1) != 0)
.map(x=>(x._1, x._2._1))
}).print()
ssc.start()
ssc.awaitTermination()
3.3 Window Operations
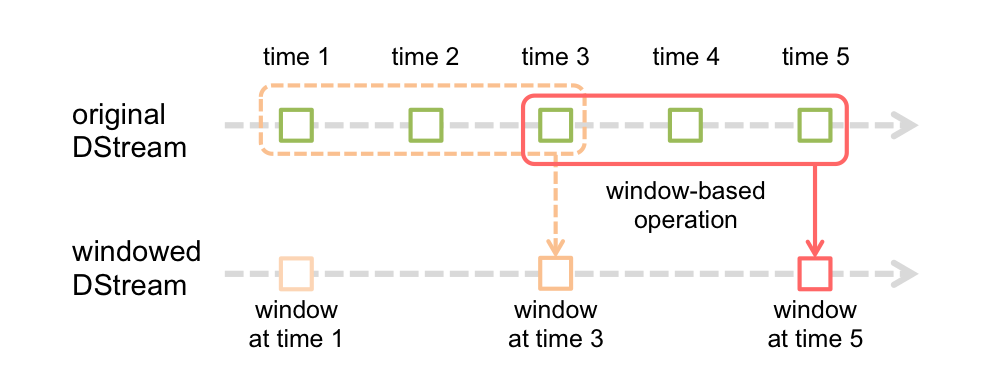
红色实线表示窗口当前的滑动位置,虚线表示前一次窗口滑动的位置,落在该窗口中的RDD被一起同时处理,生成一个DStream,窗口操作需要两个参数
- 窗口划动长度(window length):即窗口持续的时间,上图长度为3
- 滑动间隔(sliding interval):窗口操作执行的时间间隔,上图的滑动为2
设置的这两个Seconds参数,必须 是StreamingContext中Seconds参数的整数倍
窗口函数的wordCount
val ssc = new StreamingContext(conf, Seconds(1))
// 窗口函数也需要CheckPoint
ssc.checkpoint("hdfs://hadoop1:8020/user/root/streaming")
val line = ssc.socketTextStream("hadoop1", 9999)
// 会将同一个窗口长度内的值相加
line.flatMap(_.split(","))
.map((_, 1))
.reduceByKeyAndWindow((a:Int, b:Int) => a+b, Seconds(5), Seconds(1))
.print
ssc.start()
ssc.awaitTermination()
窗口函数提高效率
val ssc = new StreamingContext(conf, Seconds(1))
ssc.checkpoint("hdfs://hadoop1:8020/user/root/streaming")
val line = ssc.socketTextStream("hadoop1", 9999)
// 会将同一个窗口长度内的值相加
line.flatMap(_.split(","))
.map((_, 1))
// 效率的提高在这里 _-_, 将计算重复的地方保留
.reduceByKeyAndWindow((a:Int, b:Int) => a+b, _-_, Seconds(5), Seconds(1))
.print
ssc.start()
ssc.awaitTermination()
为什么会提高效率
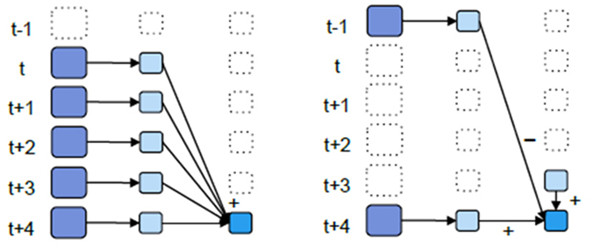
- 左图为例,每隔5秒统计wordCount,这个方式会将5秒钟的每一秒都进行统计,然后叠加。称为叠加式。
- 右图为例,计算t+4这个时刻过去5秒的wordCount,可以将t+3秒过去的5秒的统计量加上[t+3, t+4],然后再减去[t-2, t-1]的统计量,这种方式可以复用中间三秒的统计量。称为增量式。
3.4 foreachRDD
第一种方式
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // executed at the driver
rdd.foreach { record =>
connection.send(record) // executed at the worker
connection.close()
}
}
频繁地开户关闭conntection,会导致性能问题
第二种方式
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
第三种方式 使用连接pool
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}
4 Checkpointing 案例
spark streaming 自带的checkpoint是无法实现,理想的操作的。
object CheckpointTest {
val checkpointDirectory = "hdfs://hadoop1:8020/user/root/streaming"
def main(args: Array[String]): Unit = {
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
// 不要在这里写计算逻辑,不信? 你可以试试
context.start()
context.awaitTermination()
}
def functionToCreateContext(): StreamingContext = {
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("functionToCreateContext")
val ssc = new StreamingContext(conf, Seconds(5))
val lines = ssc.socketTextStream("hadoop1", 9999)
lines
.flatMap(_.split(","))
.map((_,1))
.updateStateByKey(updateFunction _)
.reduceByKey(_+_).print()
ssc.checkpoint(checkpointDirectory)
ssc
}
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = newValues.sum + runningCount.getOrElse(0)
Some(newCount)
}
}
友情链接:

