Hive优化
1 Hive性能优化方式
1.1 join性能优化介绍
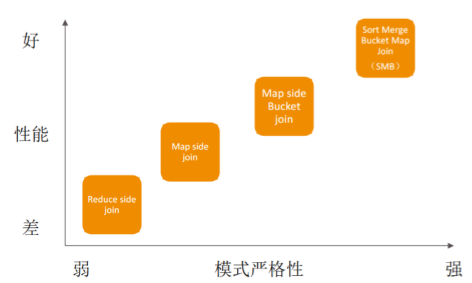
从上图可以看出Reduce端join的性能最差,因为其要经过Shuffle阶段。
比其好上一些的在Map端join,如果性能还达不到要求则在Map端Join的基础之上将表分桶。
将分桶进行排序然后进行join操作
1.2 map端join和reduce端join区别
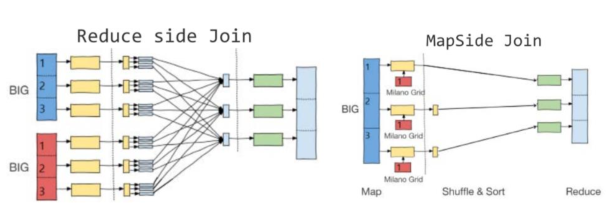
1.3 map端Join条件
- 大表和小表join,小表可以完全放入内存
- bucket表之间join
1.4 Sort Map Bucket 简称 SMB
首先进行打排序,然后合并,再放到相应的bucket中去。
- 需要在每个桶中按相同字段排序
- 打开设置,
set hive.auto.convert.sortmerge.join=true;
1.5 查询性能优化
- 使用join优化特性
- IO优化
- 减少读取数据量(使用分区表)
- 使用列示存储
- 启动数据压缩
- 增加并行度
- 设置Mapper和Reducer的数量
1.6 列式存储
Record Columnar File
- 更快地加载
- 更快速的查询
- 更高效的存储空间利用率
2 简介 实战
举个例子:比如男uv,女uv,像淘宝一天30亿的pv,如果按性别分组,分配2个reduce,每个reduce处理15亿数据。
面对这些问题的优化手段:
- 好的模型设计事半功倍。
- 解决数据倾斜问题。
- 减少job数。
- 设置合理的map reduce的task数,能有效提升性能。
- 了解数据分布,自己动手解决数据倾斜问题是个不错的选择。set hive.groupby.skewindata=true;这是通用的算法优化,但算法优化有时不能适应特定业务背景,开发人员了解业务,了解数据,可以通过业务逻辑精确有效的解决数据倾斜问题。
- 数据量较大的情况下,慎用count(distinct),count(distinct)容易产生倾斜问题。
- 对小文件进行合并,是行至有效的提高调度效率的方法,假如所有的作业设置合理的文件数,对云梯的整体调度效率也会产生积极的正向影响。
- 优化时把握整体,单个作业不如整体最优。
2.1 hive性能低下根源
RAC(Real Application Cluster)真正应用集群就像一辆机动灵活的小货车,响应快;
Hadoop就像吞吐量巨大的轮船,启动开销大,如果每次只做小数量的输入输出,利用率将会很低。
所以用好Hadoop的首要任务是增大每次任务所搭载的数据量。
Hadoop的核心能力是parition和sort,因而这也是优化的根本。
hadoop 处理数据的过程,显著特征:
- 数据的大规模并不是负载重点,造成运行压力过大是因为运行数据的倾斜。
- jobs数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联对此汇总,产生几十个jobs,将会需要30分钟以上的时间且大部分时间被用于作业分配,初始化和数据输出。M/R作业初始化的时间是比较耗时间资源的一个部分。
- 在使用SUM,COUNT,MAX,MIN等UDAF函数时,不怕数据倾斜问题,Hadoop在Map端的汇总合并优化过,使数据倾斜不成问题。
- COUNT(DISTINCT)在数据量大的情况下,效率较低,如果多COUNT(DISTINCT)效率更低,因为COUNT(DISTINCT)是按GROUP BY字段分组,按DISTINCT字段排序,一般这种分布式方式是很倾斜的;比如:男UV,女UV,淘宝一天30亿的PV,如果按性别分组,分配2个reduce,每个reduce处理15亿数据。
- 数据倾斜是导致效率大幅降低的主要原因,可以采用多一次 Map/Reduce 的方法, 避免倾斜。
最后得出的结论是:避实就虚,用 job 数的增加,输入量的增加,占用更多存储空间,充分利用空闲 CPU 等各种方法,分解数据倾斜造成的负担。
2.2 配置角度优化
我们也可以从Hive的配置解读去优化。Hive系统内部已针对不同的查询预设定了优化方法,用户可以通过调整配置进行控制。
2.2.1 列裁剪
只读取查询中所需要的列,而忽略其它列。
select a,b from q where e < 10;
裁剪所对应的参数项为:hive.optimize.cp=true(默认值为真)
2.2.2 分区裁剪
可以在查询的过程中减少不必要的分区。
select * from (select a1, count(1) from t group by a1) subq where subq.prtn=100; # (多余分区)
SELECT * FROM T1 JOIN (SELECT * FROM T2) subq
on (T1.a1=subq.a2) where subq.part=100;
查询语句若将subq.prtn=100条件放入子查询中更为高效,可以减少读入的分区 数目。 Hive 自动执行这种裁剪优化。
分区参数为:hive.optimize.pruner=true(默认值为真)
3 join操作
-
在编写带有join操作代码语句时,应该将条目的表/子查询放在Join操作符的左边。
- 因为在reduce阶段,位于join左边的内容会被加载进内存,载入条目较少的表,可以有效的减少OOM(out of memory)即内存溢出。
- 所以对于同一个key来说,对应的 value 值小的放前面,大的放后面, 这就是“小表放前原则”。
3.1 join原则
小表在前:
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x on (u.userid = x.userid)
- 如果 join 的 key 相同, 不管有多少表,都会合并为一个mapreduce
- 一个map-reduce任务, 而不是”N”个
- 在做Out join 也一样
Join条件不同时
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x on (u.age = x.age);
Map-Reduce 任务数目和Join操作数目是对应的,上述查询和以下查询是等价的:
INSERT OVERWRITE TABLE tmptable
SELECT * FROM page_view p JOIN user u
ON (pv.userid = u.userid);
INSERT OVERWRITE TABLE pv_users
SELECT x.pageid, x.age FROM tmptable x
JOIN newuser y ON (x.age = y.age);
3.2 MAP JOIN操作
map 端join 条件:
- 大表和小表join, 小表可以完全放入内存
- bucket表之间join
Join 操作在 Map 阶段完成,不再需要Reduce,前提条件是需要的数据在 Map 的过程中可以访问到。
INSERT OVERWRITE TABLE pv_users
SELEST pv.pageid, u.age
FROM page_view pv
JOIN user u ON (pv.userid = u.userid)

相关参数:
hive.join.emit.interval = 1000
hive.mapjoin.size.key = 10000
hive.mapjoin.cache.numrows = 10000
3.3 GROUP BY 操作
进行GROUP BY操作时需要注意一下几点:
- Map端部分聚合
不是所有的聚合操作都需要在reduce部分进行,很多聚合操作都可以先在Map端进行部分聚合,然后reduce端得出最终结果。
这里需要修改的参数为:
hive.map.aggr=true(用于设定是否在 map 端进行聚合,默认值为真)
hive.groupby.mapaggr.checkinterval=100000(用于设定 map 端进行聚合操作的条目数)
- 有数据倾斜时进行负载均衡
- 此处需要设定
hive.groupby.skewindata,当选项设定为 true 是,生成的查询计划有两 个 MapReduce 任务。 - 在第一个 MapReduce 中,map 的输出结果集合会随机分布到 reduce 中, 每个 reduce 做部分聚合操作,并输出结果。这样处理的结果是,相同的 Group By Key 有可 能分发到不同的 reduce 中,从而达到负载均衡的目的;
- 第二个 MapReduce 任务再根据预处理的数据结果按照 Group By Key 分布到 reduce 中(这个过程可以保证相同的 Group By Key 分布到同一个 reduce 中,最后完成最终的聚合操作。
- 此处需要设定
4 合并小文件
我们知道文件数目小,容易在文件存储端造成瓶颈,给 HDFS 带来压力,影响处理效率。对此,可以通过合并Map和Reduce的结果文件来消除这样的影响。
合并小文件参数有:
是否合并Map输出文件:hive.merge.mapfiles=true(默认值为真)
是否合并Reduce端输出文件:hive.merge.mapredfiles=false(默认值为假)
合并文件的大小:hive.merge.size.per.task=256*1000*1000(默认值为 256000000)
5 优化常用手段
主要这三个属性决定:
hive.exec.reducers.bytes.per.reducer #这个参数控制一个job会有多少个reducer来处理,依据的是输入文件的总大小。默认1GB。
hive.exec.reducers.max #这个参数控制最大的reducer的数量, 如果 input / bytes per reduce > max 则会启动这个参数所指定的reduce个数。 这个并不会影响mapre.reduce.tasks参数的设置。默认的max是999。
mapred.reduce.tasks #这个参数如果指定了,hive就不会用它的estimation函数来自动计算reduce的个数,而是用这个参数来启动reducer。默认是-1。
参数设置的影响
- 如果reduce太少:如果数据量很大,会导致这个reduce异常的慢,从而导致这个任务不能结束,也有可能会OOM
- 如果reduce太多: 产生的小文件太多,合并起来代价太高,namenode的内存占用也会增大。如果我们不指定mapred.reduce.tasks, hive会自动计算需要多少个reducer。

