Impala简介
简介
- 提供对HDFS、Hbase数据的高性能、低延迟的交互式 SQL查询功能
- 是一个分布式、大规模并行处理(MPP)的服务引擎
- 内存计算的Hive,兼顾数据仓库、实时、批处理、多并发等优点
- 首选PB级数据实时查询分析引擎
1 Impala架构
1.1 SMP: share everything
对称多处理器结构
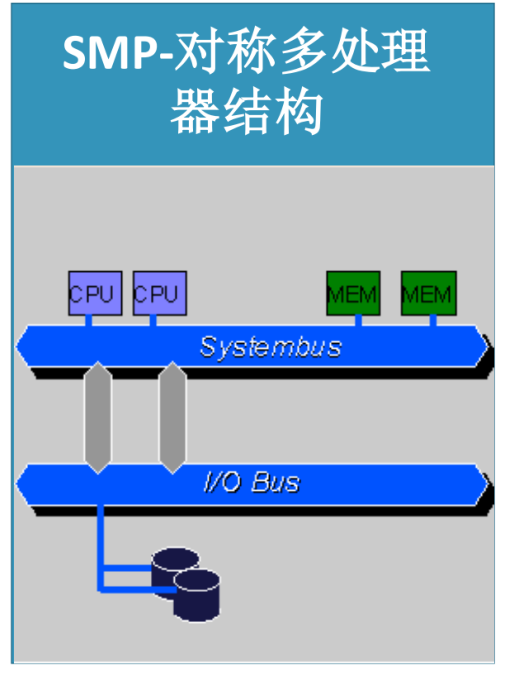
共享所有资源。多个CPU之间没有区别,平等地访问内存、外设、一个操作系统。操作系统管理着一个队列,每个处理器依次处理队列中的进程。
- 优点:运行任务很快
- 缺点:横向扩展差,节点数量大了以后,再横向扩展集群性能提升很小。
MPP: share nothing
海量并行处理
MPP 由多个SMP服务器通过一定的节点互连, 协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。
- 优点:当数据达到一定规模,mpp效率比smp好。
- 不足:节点之间通信,需要通过网络传输。
NUMA:share something
NUMA 服务器的基本特征是具有多个 CPU 模块,每个 CPU 模块由多个 CPU 组成,并且具有独立的本地内存、 I/O 槽口等。由于其节点之间可以通过互联模块 进行连接和信息交互,因此每个 CPU 可以访问整个系统的内存。
- 每个 CPU 可以访问整个系统的内存,访问本地内存的速度将远远高于访问远地内存。
- 缺点:当CPU数量增加时,系统性能无法线性增加。
Impala各进程角色
- Statestore Daemon
- 负责收集分布在集群中各个impalad进程的资源信息、个节点健康状况,同步节点信息
- 负责query的调度
- Catalog Daemon
- 分发表的元数据信息到各个impalad
- 接收来自statestore的所有请求
- Impala Daemon
- 接收client、hue、jdbc/odbc请求、query执行并返回给中心协调节点子节点上的守护进程,负责向 statestore 保持通信,汇报工作
Impala 架构
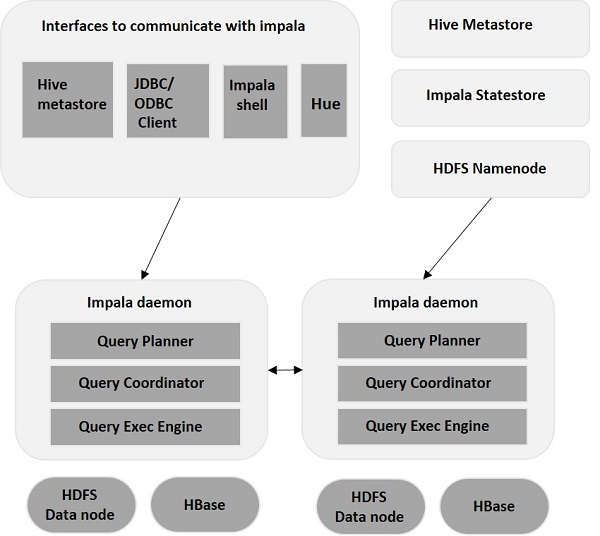
impalad
Impala核心进程,安装在Impala每个节点上
- 接受客户端查询请求,并进行处理
- 当查询提交特定节点的impalad时, 该节点充当查询的“节点协调器”。
- 接受查询后,Impalad读取和写入数据文件,并将工作发到Impalad集群中的其他Impalad节点来并行化查询
- 当查询处理各种Impalad实例时,所有查询都将结果返回到中央协调节点。
state store
可以运行在Impala服务器或集群中的其他节点的同一节点上运行
- 它负责检查每个Impalad的运行状况,不断地将每个Impalad运行状况发送给所有impalad进程节点。
- 一旦发生故障,statestore将更新所impalad进程节点关于此故障
statestore并非关键进程,即使不可用,impalad进程节点间仍然可以相互协调正常对外提供分布式查询。
metasotre
表和列信息和表定义的重要细节存储在称为元存储的集中式数据库中。
- 每个impala 节点在本地缓存所有元数据
- 当表定义或表格数据更新,其他impala后台进程必须通过检索最新元数据来更新其元数据缓存
查询处理接口
CLI:用户查询的命令行共组,还提供了Hue、JDBC、ODBC等接口。
-
Impala-shell - 使用Cloudera VM设置Impala后,可以通过在编辑器中键入impala-shell命令来启动Impala shell。 我们将在后续章节中更多地讨论Impala shell。
-
Hue界面 - 您可以使用Hue浏览器处理Impala查询。 在Hue浏览器中,您有Impala查询编辑器,您可以在其中键入和执行impala查询。 要访问此编辑器,首先,您需要登录到Hue浏览器。
-
ODBC / JDBC驱动程序 - 与其他数据库一样,Impala提供ODBC / JDBC驱动程序。 使用这些驱动程序,您可以通过支持这些驱动程序的编程语言连接到impala,并构建使用这些编程语言在impala中处理查询的应用程序。
impala查询数据流程
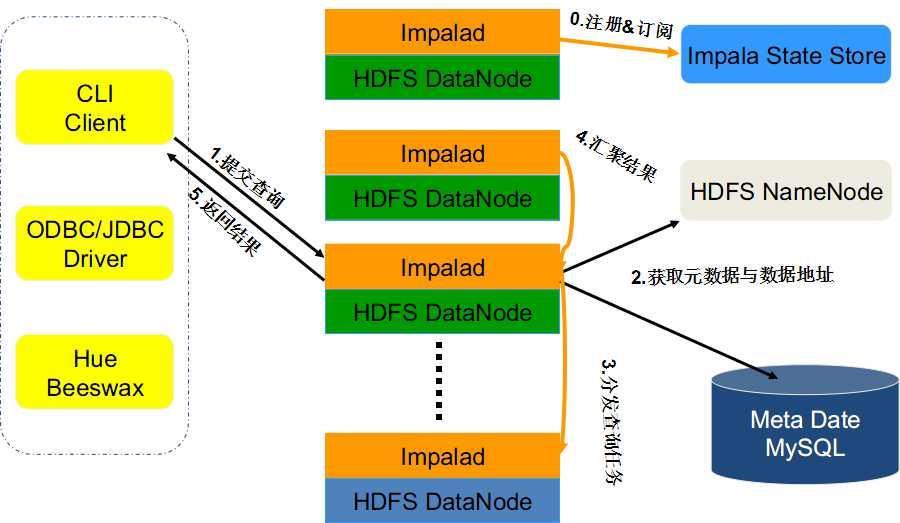
- client 提交查询任务
- 其中一个impalad进程接受查询任务, 此impalad被定为“查询协调程序”。(类似中心节点)
- 接受到查询后,使用Hive元存储中的表模式验证查询是否合适。
- 中心impalad, 获取元数据信息和datanode地址。
- 所有其他impalad读取指定的数据块并处理查询
- 所有进程完成任务,中心impalads将收集结果并将其传递给client。
Impala 优势
- 基于内存计算
- Impala直接通过对应的服务进程来进行作业调度,省掉了MR作业启动的开销
- 使用MPP并行数据库的思想,省掉不必要的shuffle、sort等开销
- 使用C++实现,并做了硬件优化
- 使用data local的IO调度制度,减少网络开销
Impala资源管理器
- 静态资源池
- CDH 中将各服务彼此隔开,分配专用资源。
- 动态资源分配
- 用于配置及用于在池中运行的yarn或impala查询之间安排资源的策略
Impala和yarn:Impala2.3之前,使用yarn做资源调度 2.3之后,自身的资源调度策略Long-Lived Application Master,LIAMA
相关参数
- set request_pool=impala10001;
- 将查询语句提交到名字叫impala10001 的资源池
- set men_limit=10kb
- explain select count(*) from …where …
- 设置本次执行语句内存限制
- set explain_level=3;
- 设置执行计划显示的详细程度,等级越高越详细
- 一般使用默认的,就足够了
- INVALIDATE METADATA
- 全部同步,一般不推荐使用
- REFRESH
refresh work.userinfo- 推荐使用,同步指定的数据

