Hive的架构和操作
hive简介
直接使用hadoop所面临问题
- 人员学习成本太高
- 项目周期要求太短
- MapReduce实现复杂查询逻辑开发难度太大
为什么使用hive
- 操作接口采用类SQL语法,提供快速开发的能力。
- 避免了去写MapReduce,减少开发人员的学习成本。
- 扩展功能很方便。
hive架构
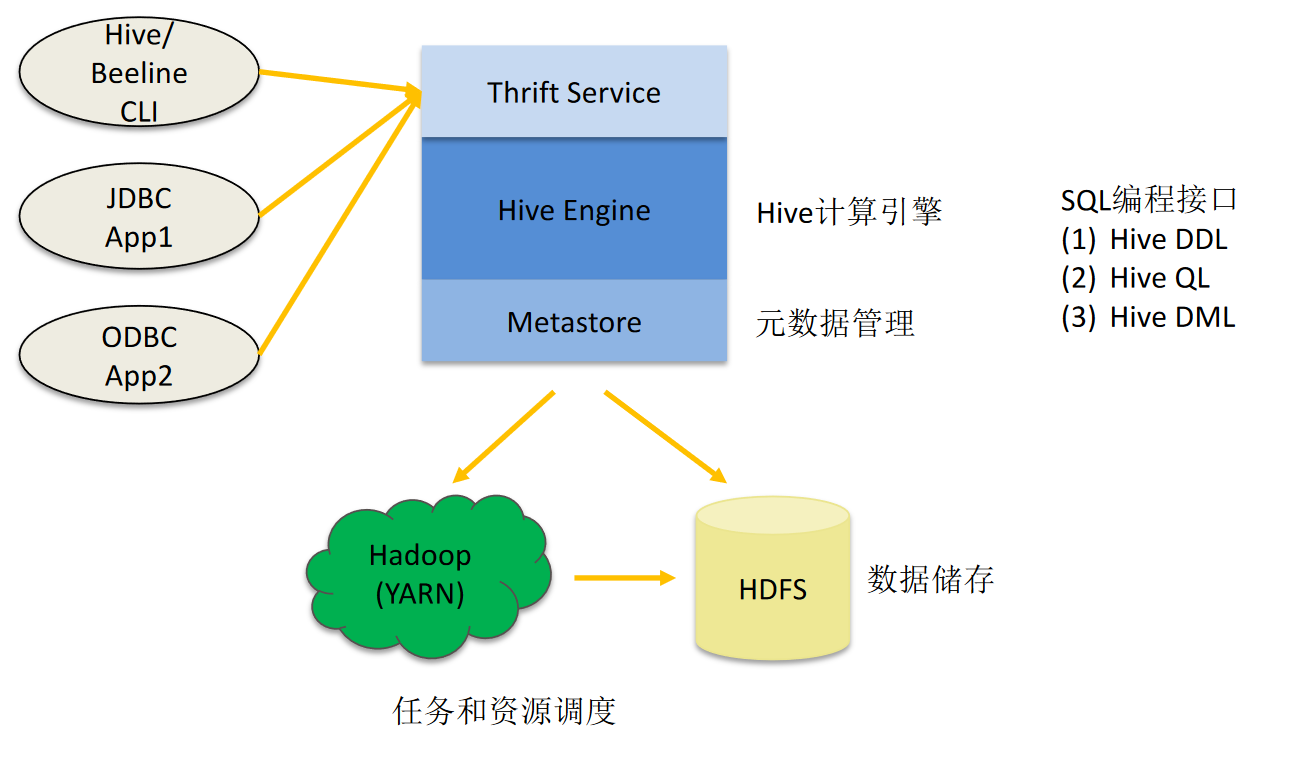
基本组成
- 用户接口:包括 CLI、JDBC/ODBC、WebGUI。
- 元数据存储:通常是存储在关系数据库如 mysql , derby中。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
- Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
各组件功能
- 用户接口主要有三个:CLI、JDBC/ODBC、WebGUI。
- CLI为shell命令行
- JDBC/ODBC是hive的java实现,与传统jdbc相似
- WebGUI通过浏览器访问hive
- 元数据存储:Hive将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
Hive利用HDFS存储,利用MapReduce查询数据
Hive的数据存储
- Hive 中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)。
- 只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
- Hive 中包含以下数据模型:DB、Table、External Table、 Partition、 Bucket。
- db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
- table:在hdfs中表现所属db目录下一个文件夹
- external table:与table类似,不过其数据存放位置可以在任意指定路径
- partition:在hdfs中表现为table目录下的子目录
- bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件
使用方式
Hive thrift服务
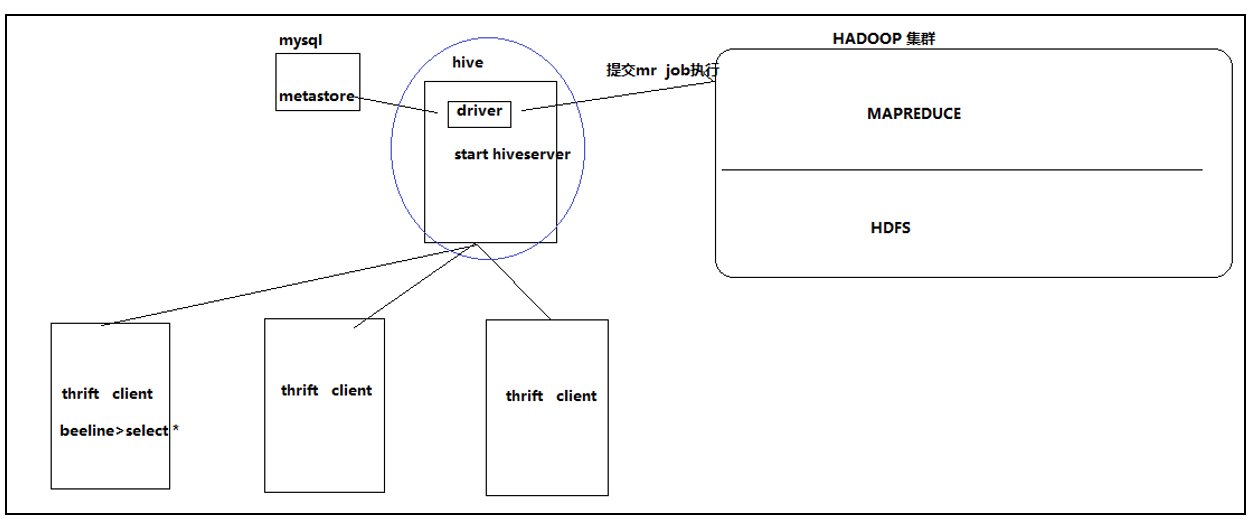
启动方式:
- 在前台启动:
bin/hiveserver2 - 启动为后台:
nohup bin/hiveserver2 1>/var/log/hiveserver.log 2>/var/log/hiveserver.err &
启动成功,可以在别的节点上用beeline去链接:
- hive/bin/beeline 回车,进入beeline的命令界面
输入命令连接hiveserver2,
beeline> !connect jdbc:hive2//mini1:10000 - 或者启动就连接,
bin/beeline -u jdbc:hive2://mini1:10000 -n hadoop
表分区或分桶的理由
把表(或者分区)组织成桶(Bucket)有两个理由:
- 分区是独立一列为分区列,是为了获得更高的查询处理效率。
- 桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。
- 具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如join操作。对于join操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
- 使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
Hive函数区别
- 1:1 函数Functions (UDFS=User Defined Functions) map阶段
- N:1 聚合函数Aggregate Functions Reduce阶段
- 1:n 表生成函数Table-genderating functions(UDTFS) 都可以
- m:n 分区表函数Partitioned table functionsPTF
Hive表结构
分区表
一般结构,单层分区
create table partition_access_log (ip STRING, )
....
partitioned by (request_date STRING) ...;
hdfs:///access_logs/....
- 2018_11_06
- 2018_11_07
- 2018_11_08
多层分区
create table partitioned_access_long (ip STRING, )....
partition by (year STRING, moneth STRING, day STRING) ...;
分区表作用:
- 避免全表扫描
- 提升性能查询
- 方便数据写入
- 方便管理
分区表加载数据
静态分区:
from raw_accesss_log
insert overwrite table partitioned_access_log
partition(year="2017", month="03", day="25")
select ip, .......
动态分区
from raw_access_log
insert overwrite table
partitioned_access_log
partition(year, month, day)
select ip, ..., year, month, day
insert overwrite table
partitioned_access_log
partition(year, month, day)
select ip, ..., year, month, day
from raw_access_log
混合模式
from raw_access_log
insert overwrite table partitioned_access_log
partition (year="2017", month, day)
select ip,...., month day
分区动态加载数据参数
set hive.exec.max.dynamic.partitions=2048;
set hive.exec.max.dynamic.partitions.pernode=256;
set hive.exec.max.created.files=10000;
# 防止空的分区产生
set hive.error.on.empty.partition=true;
# 允许动态分区
set hive.exec.dynamic.partition.mode=nonstrict;
表分桶
create table granular_access_log( ip STRING, )...
partition by (request_date STRING)
clustered by (column_name, ...)
into 200 buckets ...;
clustered by (user_id)
hash函数:INT是取模,STRING 能保证平均分布
如果分桶和sort字段是同一个时,此时,cluster by = distribute by + sort by
分桶表的作用:最大的作用是用来提高join操作的效率;
分桶表写入数据
hive并不检查数据文件中的桶是否和表定义的桶一致。如果两者不匹配,查询时可能会碰到错误。
- 首先要把reduce的数据定义为buckets数据一致,即决定最终会产生多少个文件
- hive.enforce.sorting 和 hive.enforce.bucketing都设置为true, 就不需要手动添加distribute by 和 sort by
set mapred.reduce.tasks = 200;
from raw_access_log
insert overwrite table granular_access_log partition by (request_date)
select ..., request_date
where ...
distribute by user_id
[sort by user_id];
set hive.enforce.bucketing=true;
from raw_access_log
insert overwrite table granular_access_log partition by(request_date)
select ..., request_date
where ...;
- order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
- sort by不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并设置
mapred.reduce.tasks>1, 则sort by只保证每个reducer的输出有序,不保证全局有序。 - distribute by(字段) 根据指定的字段将数据分到不同的reducer,且分发算法是hash散列。
- Cluster by(字段) 除了具有Distribute by的功能外,还会对该字段进行排序。
SMB
- 需要在每个桶内按相同字段排序
- 打开设置
hive> SET hive.auto.convert.sortmerge.join=true
存储格式
Hive 从两个维度对表的存储进行管理,分别是行格式(row format)和文件格式(file format)。
SerDe:是“序列化和反序列化工具”的合成词。当作为反序列化工具进行使用时,也就是查询表时,SerDe将把文件中字节形式的数据行反序列为Hive内部操作数据行时所用的对象形式。
1. 默认存储格式:分隔的文本
file.default.fileformat
创建表时,没有使用row format 或 store as 子句,那么hive 使用的是默认分隔。默认分隔符不是制表符 ,而ASCII控制 码集合中的Control-A(它的ASCII码为1 也就是 \001)
create table ...
等价于
create table ...
row format delimited
fields terminated by '\001'
collection items terminated by '\002'
map keys terminated by '\003'
lines terminated by '\n'
stored as textfile;

