Hive一些常用操作
查看表结构
show tables
show databases
show partitions
show functions
desc extended t_name;
desc formatted table_name;
Hive shell常用的操作
-
hive -ehive -e “select * from db_hive.student;”
-
hive -f
一般企业里面有很多都是这种形式 $ touch hivef.sql select * from db_hive.student'; hive -f /.../hivef.sql hive -f /.../hivef.sql > /.../hivef-res.txt -
hive -i
初始化,一般与UDF结合使用
exit和quit退出的区别
- exit,会先提交数据,然后后再退出
- quit,直接退出
数据库
create database if not exists db_hive_01;
create database if not exists db_hive_01 location ‘/user/db_hive/...’;
show databases like 'db_hive*'
use db_hive;
desc database db_hive_01;
desc databases extended db_hive_01;
库中有表,不能直接删除库时,使用cascade联级删除。
drop database if exists db_hive_01 cascade;
建表语句
1. CREATE TABLE db_hive2 LIKE db_hive1;
会创建一张表db_hive2,表结构和db_hive1一样,不会复制数据。
create table if not exists db_hive.emp1(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
row format delimited fields terminated by '\t';
create table if not exists db_hive.dept(
deptno int,
dname string,
loc string
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/emp.txt' overwrite into table db_hive.emp1;
load data local inpath '/opt/datas/dept.txt' overwrite into table db_hive.dept;
hive 快速建表
create table if not exists db_hive.emp_cats
as
select empno, ename, sal from emp;
清除表数据
truncate table dept_cats;
新表旧表schema(约束)一致
create table if not exists db_hive.dept_like
like
db_hive.dept;
修改表名称 和 删除表
alter table dept_like rename to dept_like_rename;
drop table if exists dept_like_rename;
内部表和外部表
EXTERNAL_TABLE
- 删除表的时候,不会删除数据文件
- 企业里面80%都是使用外部表
- 外部表的作用,多个部门各自需要同一份原始数据的部分内容时。
create external table if not exists db_hive.emp_external( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int ) row format delimited fields terminated by '\t' location '/user/root/hive/warehouse/emp_external'; 将放在hdfs该目录下的文件自动加载到表中分区
分区就是分目录,把一个大的数据集,根据业务需要分割成一个个小的数据集。
常用场景
日志文件
/usr/.../logs
/day=20181020
20181020.log1.txt
/day=20181021
20181021.log1.txt
/day=20181022
20481022.log1.txt
create external table if not exists db_hive.emp_partition(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
PARTITIONED BY (month string)
row format delimited fields terminated by '\t'
location '/user/root/hive/warehouse/emp_partition';
load data local inpath '/opt/datas/emp.txt' into table db_hive.emp_partition
partition (month='201810');
SELECT * FROM emp_partition where month='201810';
得到一个季度的pv
SELECT COUNT(DISTINCT ip) FROM emp_partition where month='201809'
union
SELECT COUNT(DISTINCT ip) FROM emp_partition where month='201808'
union
SELECT COUNT(DISTINCT ip) FROM emp_partition where month='201807'
;
二级分区
create external table if not exists db_hive.emp_partition2(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
PARTITIONED BY (month string, day string)
row format delimited fields terminated by '\t'
location '/user/root/hive/warehouse/emp_external';
load data local inpath '/opt/datas/emp.txt' into table db_hive.emp_partition
partition (month='201810', day='21');
SELECT * FROM emp_partition where month='201810' and day='21';
分区表加载数据
- 静态分区
from raw_access_log insert overwrite table pratitioned_assess_log partion (year="2017", month="03", day="25") select ip,name,age - 动态分区
from raw_access_log instert overwrite table partitioned_assess_log partiion (year, month, day) select ip,name,age,year,month,day - 混合模式
from raw_access_log
insert overwrite table paritioned_assess_log
partion (year="2017", month, day)
select ip,...,month,day
- 分区表动态加载数据参数 ```sql set hive.exec.max.dynamic.partitions=2048; set hive.exec.max.dynamic.partitions.pernode=256; set hive.exec.max.created.files=10000; set hive.error.on.empty.partition=true; // 防止空的分区
set hive.exec.dynamic.partition.mode=nonstrict;
#### 分桶
```sql
create table granular_access_log(ip string)
....
partitioned by(request_date string)
clustered by(cloumn_name,..)
into 200 buckets..;
分桶表写入数据
- 首先要把reduce的数量定义为和buckets数量一致
hive.enforce.sorting和hive.enforce.bucketing都设置为true, 就不需要设置distribute by和sort by。
set mapred.reduce.tasks = 200;
from raw_access_log
insert overwrite table granular_access_log
partition by(request date)
select .., request_date
where ...
distribute by user_id
[sort by user_id];
set hive.enforce.bucketing=true
from raw_access_log
insert overwrite table granular_access_log
partition by(request_date)
select ...,request_date
where ...
导出数据
1.常见导出insert overwrite local directory '/opt/datas/test.txt' select * from emp;
2.定义格式
insert overwrite local directory '/opt/datas/test1.txt'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY '\n'
select * from emp;
3.hive -e "select * from ..." > /opt/datas/xx.txt
4.保存到HDFS上
insert overwrite directory ''
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY '\n'
select * from emp_partition;
5.sqoop
0.8.0新加入的
EXPORT讲hive表中的数据导出到外部,copy,会导出元数据
EXPORT TABLE emp TO '/user/root/hive/export/emp/';
导出路径指的是HDFS路径
IMPORT讲外部数据导入到hive表中
IMPORT TABLE emp_import FROM '/user/root/hive/export/emp/';
查询
select * from emp;
select t.empno, t.ename from emp t;
select * from emp limit 5;
where = >= <= between and
select t.empno, t.ename from emp t where t.sal between 800 and 1500;
select t.empno, t.ename from emp t where comm is null;
聚合 max/min/count/sum/avg
group by
1.每个部门的平均工资
select t.deptno, avg(sal) avg_sal from emp t group by t.deptno;
2.每个部门中每个岗位的最高薪水
select t.deptno, t.job, max(sal) avg_sal from emp t group by t.deptno, job;
having
where是针对单条记录进行筛选过滤,
having是针对分组结果进行筛选的
1.求每个部门的平均薪水大于2000的部门
select deptno, avg(sal) avg_sal from emp group by deptno
having avg_sal > 2000;
join
等值join
join ... on
select e.empno, e.ename, d.deptno, d.dname from emp e join dept d on e.deptno = d.deptno;
左连接
select e.empno, e.ename, d.deptno, d.dname from emp e left join dept d on e.deptno = d.deptno;
右连接
select e.empno, e.ename, d.deptno, d.dname from emp e right join dept d on e.deptno = d.deptno;
全连接
select e.empno, e.ename, d.deptno, d.dname from emp e full join dept d on e.deptno = d.deptno;
四个by
order by 全局排序,仅仅只有一个reducer
select * from emp order by empno desc;
sort by其在数据进入reducer前完成排序,对每一个reduce内部进行排序,全局结果集不是排序的
set mapreduce.job.reduces=3;
select * from emp sort by empno asc;
insert overwrite local directory '/opt/datas/sortby_res' select * from emp sort by empno asc;
distribute by 分区,类似mapreduce中partitioner,对数据分区,
通常结合sort by使用
insert overwrite local directory '/opt/datas/distby_res' select * from emp
distribute by deptno sort by empno asc;
cluster by 当distribute by的字段和sort by的字段相同时就可以用cluster by代替
insert overwrite local directory '/opt/datas/clusterby_res' select * from emp
cluster by empno asc;
表生成函数
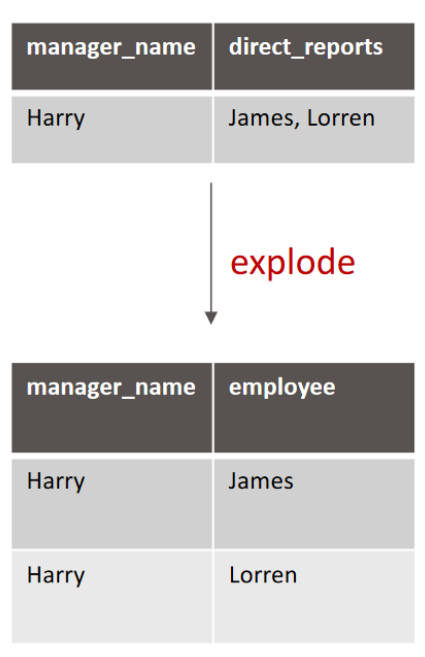
Table "Management":
manager_name (STRING)
direct_reports (ARRAY<STRING>)
select manager_name, employee
from management
lanteral view explode(direct_reports) lateral_table AS employee;
- PTF

select
customerID,
transationID chage,
sum(change) over (
partition by customerID
order by transactionID
)
from transations
sort by customerID, transactionID;

