Sqoop是什么以及简单流程
1. 问题
假设:目前正式生产环境的数据出现了错误或者是偏差(2000w)修正这些错误?
解决:利用sqoop(数据修正)
2. sqoop是什么
全称:SQL TO HADOOP
sqoop 是一个hadoop与关系弄数据库之间相互数据传输的工具。sqoop可以将数据从关系型数据库, (例如mysql或oracle或大型机) 导入到hdfs,转换成MapReduce数据,然后将数据导回到关系型数据库。
sqoop的import依赖数据库的描述约束。
sqoop本质是mapreduce,但是仅存在Map task。
sqoop 将sql转化成.java文件打成jar包执行mapreduce
sqoop 执行流程
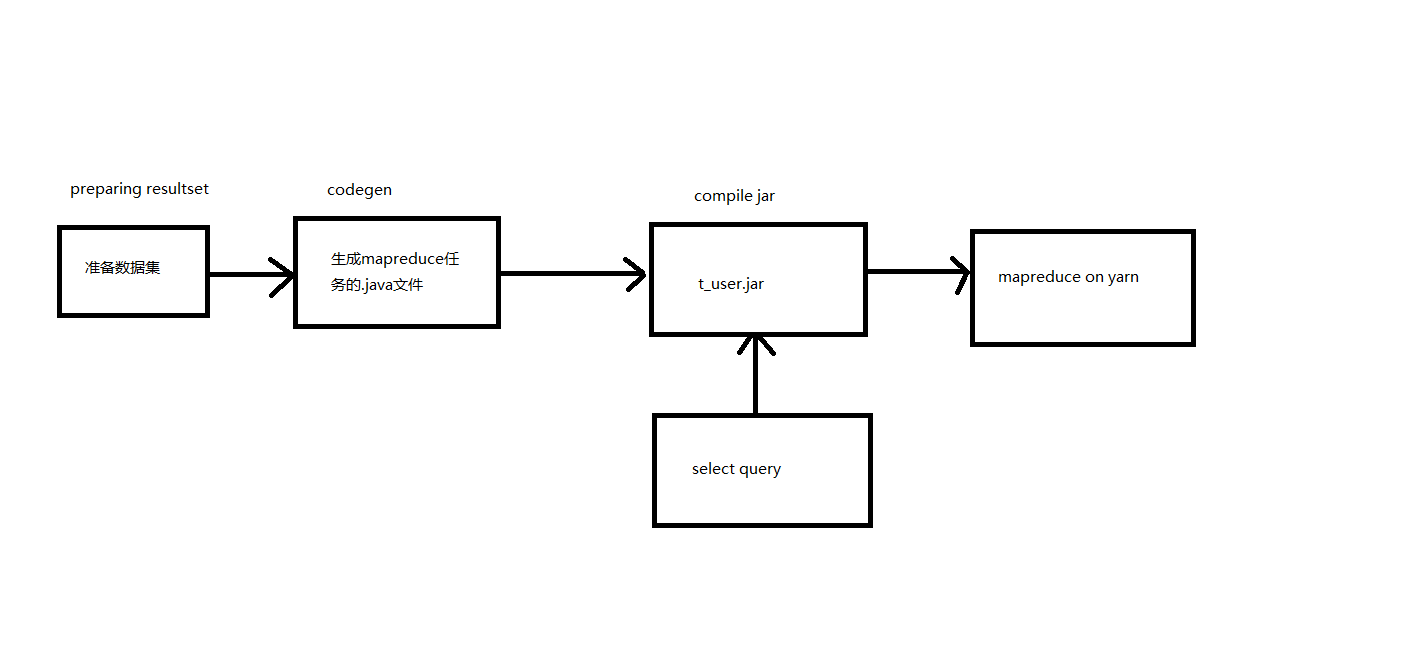
- 准备数据集 (preparing resultset)
- 生成mapreduce,.java文件 (codgen)
- 打成jar包, (compile jar)
- 执行查询拉取数据
- 到yarn上执行map task (mapreduce on yarn)
3. 环境依赖
- hadoop
- hive
- hbase
- zookeeper
4. 基础用法
- 对于数据库,sqoop将逐行导入hdfs。
- 对于大型的数据集,sqoop从不同的大型数据集读记录到hdfs。
- 导入的进程是并行的
通用链接参数
sqoop 连接数据库三要素:
--connect <jdbc-uri> 指定要连接的数据库
--username <username> 访问数据库的用户名
--password <password> 访问数据库的密码
--table TEST 设置要访问的表
5. Import
sqoop import --connect jdbc:mysql://hadoop1/test \
--username root \
--password 123456 \
--table book_info
--columns book_name, book_type \
--fields-terminated-by '\t' \
--delete-target-dir \
--num-mappers 1 \
--direct
- num-mappers:指明map task的数目
- direct,是msql中提高查询 效率的工具 mysqldump,
select * from xx - columns 指定列
- fields-terminated-by 指定分隔符
- delete-target-dir 如果文件存在则删除, 不能和增量导入一起使用
注意:如果要使用direct参数,需要将mysqldump文件添加每台datanode的/usr/bin下也就是说mysqldump操作是由集群中的datanode节点来执行。
指定文件来执行sqoop
sqoop --options-file /users/homer/work/import.txt --table TEST
- options-file:指定文件读取目录。
- fields-terminated-by:指定内容行字段的分隔符,默认以逗号分割。
- delete-target-dir:如果导入的hdfsh目录存在,则删除。
- target-dir:指定import,导入的hdfs路径。
Import to Hive
--hive-import
--hive-database <database-name>
--hive-table <table-name>
hive的日志,除了在hive下,还可以有tmp下可以看到
java.lang.ClassNotFoundException:找不到对应jar包
需要将对应的依赖包导入到 sqoop/lib包下
hive/lib/jdo-*-.jar
hive-*-.jar
antlr-*-.jar
calcite-*-.jar
datanucleus-*-.jar
拷贝hive/conf/hive-site.xml到sqoop/conf下
