Spark核心技术,运行流以及SparkRDD基本
1. 什么是Spark
Spark 以前是一个单一的内存计算机框架,发展至今成为一个独立的生态系统
现在基本每年都会在北京,深圳开设一些关于Spark的相关圆桌会议
相对于Spark来说,有一个相似的计算机框架,Storm。Storm是一个纯粹的实时计算框架
Spark支持离线计算,通过SQL的方式进行数据处理、分析
此外也具备Streaming的准实时计算机方式。
- 是一个由Scala编写的、支持复杂运算的、基于内存的、准实时的大数据计算框架
- 同时也支持离线计算机
- 通过SQL的方式进行数据处理、分析
- 具备Streaming的准实时计算机方式
Spark能替代Hadoop吗?
不能, Spark不能代替Hadoop的主要原因,不是在于技术框架, 而是在于业务场景。
Spark很快?(不算Streaming)
相对于Hadoop, Hadoop跑1时间,Spark10分钟、 Hadoop跑1天,Spark跑1小时
1.1 Spark集群概述
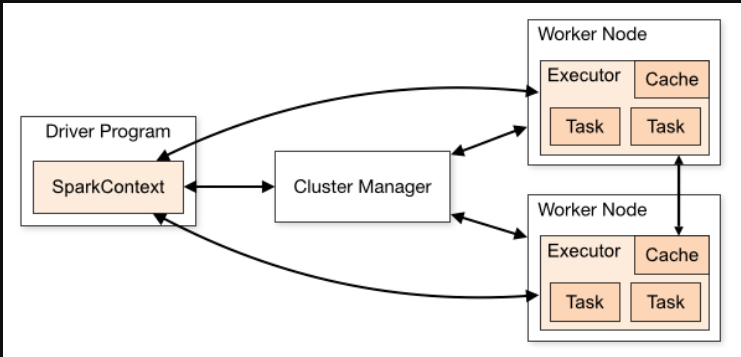
角色介绍
- Dirver Program
- 编写的Spark程序
- SparkContext
- 在每个Driver Program中都会存在一个SparkContext
- SparkContext主要用于跟Spark集群进行交互(申请计算资源,配置我们任务调度机制…)
- Cluster Manager
- 管理Spark集群以及与Driver Program中的SparkContext进行交互
- Worker Node
- 就是一台Spark集群中的计算机节点,通常与DataNode是同一台(数据本地化)
- 每台Worker都具有一定的Cpu Cores和Memory
- Executor
- Executor是一个进程,是Spark集群中,资源分配的最小单元
- 一个Driver Program 会拥有多个Executor
- 一个Worker Node下会产生多个Executor
- 但Executor本身只做任务的管理与调度
- Task
- Task是一个线程, Driver Program中的每一个RDD操作都会转换成一个Task任务
- Driver Program会将一批Task发送到Excutor中
- 由Excutor来管理执行Task,将结果反馈给SparkContext中
2 什么是RDD
2.1 RDD(弹性分布式数据集)
- 不可变
- 只读
- 具有自动容错恢复机制(DAG,有向无环图)
- 具有优先选择数据处理节点位置的机制(计算本地化)
- 本身并不是数据集,而一个并行处理数据集的工具
2.2 内部每个RDD有以下主要的五个属性
- 分区列表(集合)
- 第一个分片,都具备 一个计算函数
- 每个RDD都有一个RDD依赖列表,用于找到当前RDD转换所需要的其他RDD
- 可选的,针对 KV类型的RDD分区器,例如:
HashPartitioner,RangePartitioner - 可选的,对于每一个的分片的优先计算机位置列表,例如从HDFS中读取文件,每个分区默认对应一个Block
2.3 RDD两种数据集创建方式
- 并行化集合
- 参考主机的
cpu core的数量 - 划分的分区数一般是
cpu core的两倍
- 参考主机的
- 外部数据集,例如
HDFS,AWS,S3- 默认情况下,
HDFS上文件对应的BLOCK数量有多少,Spark就有多少Partition - 可以大于当前
BLOCK数量 的partition,但最低不能低于HDFS上的block数量。
- 默认情况下,
2.4 RDD动作
- Transformation
- 主要是多个RDD之间数据的转换 (Lazy)
- Action
- 主要的用于最终的数据聚合,数据转换后的计算结果
- 每次调用一个Action操作时, 每一个RDD都会重新被计算
只有在执行Action时,才会触发Spark的任务调度与计算, Transformation是一个Lazy操作。
- 可以通过将RDD持久化到内存中的方式,来避免RDD被重复计算。
- 可以使用persist 或者 cache方法(cache底层调用的就是persist)
2.5 RDD 缓存、持久化(persist)
Spark非常快速的原因之一,就是在不同的操作中在内存中持久化一个数据集。
当持久化一个数据集后,每个节点都将把计算的分片结果,保存在内存中,并在此数据集后面进行的(action)操作,会对其进行重用。这使用后续动作变得更加迅速(通常快10倍)。
假设首先进行RDD0 -> RDD1 -> RDD2的计算作业,那么计算结束时,RDD1就已经缓存在系统中。在进行RDD0 -> RDD1 -> RDD3的作用时,由于RDD1已经缓存在系统中,只需进行RDD1 -> RDD3,因此计算速度可以得到很大提升。
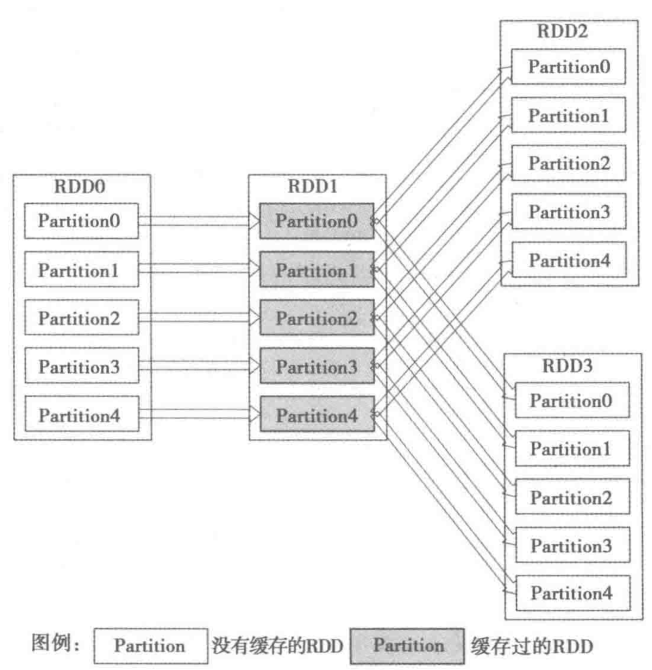
2.5.1 两种持久化方法
- persist
- cache(底层调用persist方法)
2.5.2 Spark持久化级别
| 持久化级别 | 含义解释 |
|---|---|
| MEMORY_ONLY | 默认级别,如果cache中的元素无法全部缓存到内存中,则丢失一部分。 有一部分数据还是会重新计算(数据无法完全存储到内存中)。数据没有经过序列化 |
| MEMORY_AND_DISK | 优先将数据存储到内存中。如果内存不够,就将数据存储到磁盘。 |
| MEMORY_ONLY_SER | 为了节省更多空间,我们可以先数据序列化,然后在存储在内存中。推荐使用Kryo serialization进行序列化。 |
| MEMORY_AND_DISK_SER | 基本含义与MEMORY_AND_DISK相同。唯一的区别是, 会将RDD的数据进行序列化。 |
| DISK_ONLY | 使用未序列化Java对象格式,将数据存储到磁盘文件中 |
| MEMORY_ONLY_2 | cache的数据会具有多少个副本 |
2.5.3 这么多持久化,哪家强(应该使用哪种)?
Spark的优势在于内存,如果还向磁盘上写入数据,那么会成为Spark版的Hadoop。
不要往磁盘上进行Cache上,磁盘的读写速度还不如在内存中重新做计算。
2.6 缓存的使用场景?
- 获取大量数据之后,比如来自外部数据源
- 进行一个非常长的计算链条
- 某个计算非常耗时
- 进行
checkpoint之前
2.6.1 如何选择持久化策略?
-
优先使用
MEMORY_ONLY -
内存放不下就使用
MEMORY_ONLY_SER,但会额外消耗CPU资源 - 容错恢复使用
MEMORY_ONLY_2 - 尽量不适用
DISK相关策略
2.7 RDD Checkpoint(检查点)
Checkpoint 的引入: 如果缓存丢失了,则需要重新计算。但有的时候,计算特别复杂或计算特别耗时,那么缓存丢失对于整个Job是影响是非常大的。
Checkpoint机制:计算完成后,重新建立一个Job来计算。为了避免重复计算,推荐先将RDD进行缓存。
2.8 Shared Variables
Broadcast Variables(广播变量)- 广播变量就是一个全局只读的变量或集合。
- 因为我们没有必要把每一个相关变量都往我们的Executor进行拷贝
Accumulators(累加器)- 定义个全局的累加变量(只能做累加),用于所有的Executor执行全局累加操作
3 RDD 的转换和DAG生成
3.1 缓存的处理
如果存储级别不是NONE,那么先检查是否在缓存,没有则进行计算。
缓存的级别是什么?
- 数据保存到不同的位置,比如内存,硬盘,Tachyon
- 缓存的数据是否需要序列化
RDD的第个Partition对应Storage模块的一个Block,Block是Partition处理后的数据。
3.1.1 WordCount 流程
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val textFile = sc.textFile("C:\\Users\\13194\\Desktop\\test.txt")
val wordsRdd = textFile.flatMap(_.split(" "))
val wordsCountRdd = wordsRdd.map((_, 1)).reduceByKey(_+_)
wordsCountRdd.collect().foreach(println)
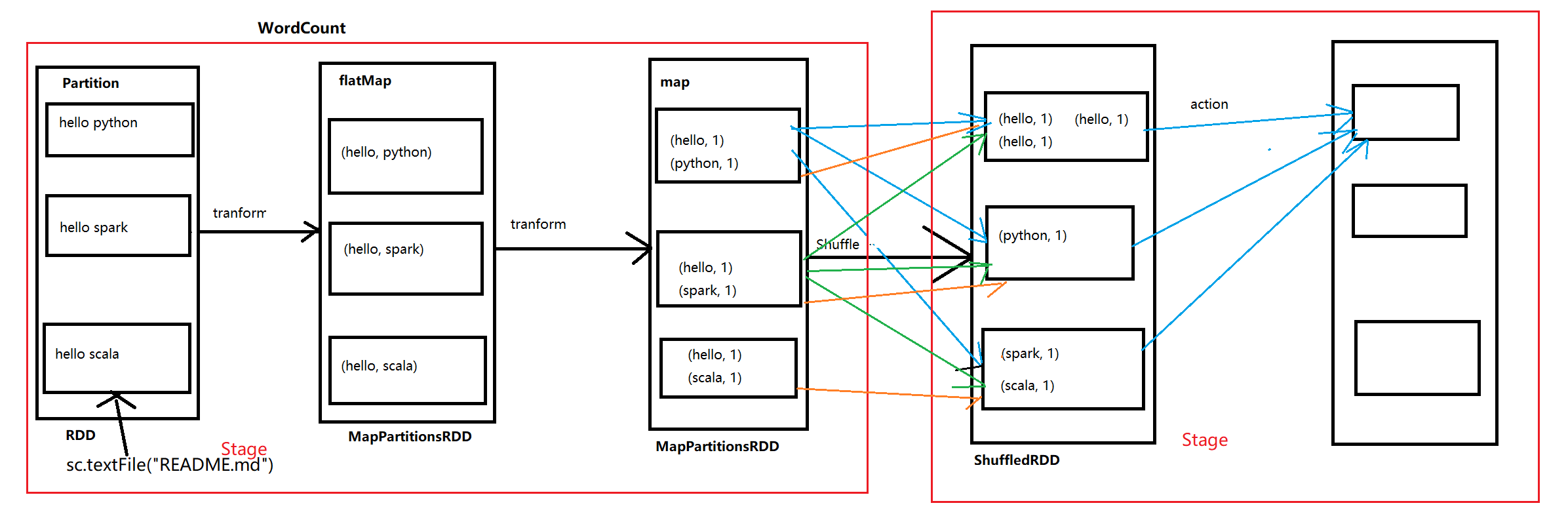
- Action主要是为了触发Spark的计算任务,每一个Transform都会转成一个Task任务执行,当到Shuffle Task时,会进行Shuffle
- 整个计划流程根据具体的流程划分不同的Stage(不同的执行部分)
- 优先使用reduceByKey来代替groupByKey(优化)
- 使用ReduceByKey会有一个本地优化,在本地将数据进行合并。
3.2 RDD 依赖关系
- 窄依赖(narrow dependency):每一个parent RDD的partition最多被子RDD的一个Partition使用,只是将数据根据转换规则进行转化,并不涉及其它处理(没有shuffle)。
- 宽依赖(wide dependency):多个子RDD的Partition会依赖同一个parent RDD的Partition,因此需要shuffle过程。
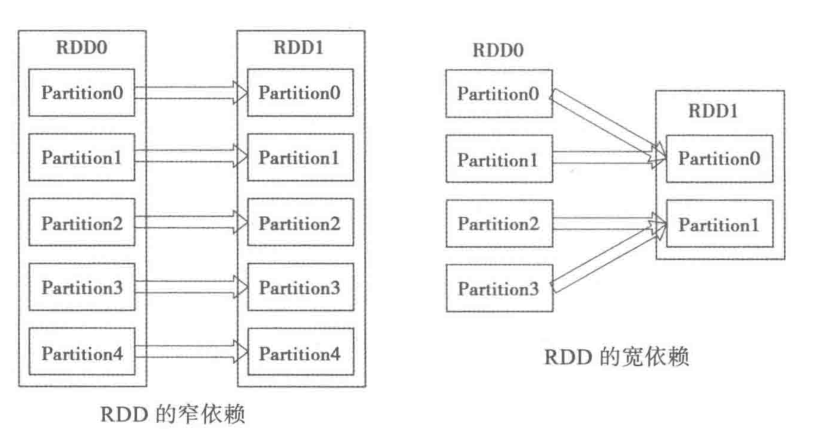
所有的依赖都要实现trait Dependency[T]:
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}
窄依赖的具体实现:
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
// 返回子RDD的partitionID依赖的所有Parent RDD的Partition(s)
def getParents(partitionId: Int): Seq[Int]
override def rdd: RDD[T] = _rdd
}
两种窄依赖的具体实现
OneToOneDependency:一对一依赖
// RDD仅仅依赖于parentRDD相同ID的partition
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int) = List(partitionId)
}
RangeDependency:范围依赖,它仅仅被org.apache.spark.rdd.UnionRDD使用
// Union仅仅是将多个RDD合并成一个RDD,每个Parent RDD中的Partition相对顺序不会变
// 只不过每个Parent RDD在Union RDD中的partion的起始位置不同
override def getParents(partitionId: Int) = {
// inStart parentRDD的Partion中的起始位置
// outStart 是UnionRDD中的起始位置
// length parentRDD中的Partition的数量
if (partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}
宽依赖的实现: ShuffleDependency
class ShuffleDependency[K, V, C](
@transient _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Option[Serializer] = None,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] {
override def rdd = _rdd.asInstanceOf[RDD[Product2[K, V]]]
val shuffleId: Int = _rdd.context.newShuffleId()
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.size, this)
_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
}
宽依赖支持两种Shuffle Manager
org.apache.spark.shuffle.hash.HashShuffleManager基于Hash的Shuffle机制org.apache.spark.shuffle.sort.SortShuffleManager基于排序的Shuffle
3.2.1 RDD Lineages(生命线,血统)
-
RDD也是一个DAG的任务集合,一个DAG代表了一个RDD的计算过程
-
每个DAG都会记住创建该数据集需要哪些操作,跟踪记录RDD的继承关系
- 保证每一个RDD被计算前,它所依赖的parent RDD都已经完成了计算
- 同时保证了RDD的容错性
3.3.2 Transfermations 常见的窄依赖
map、flatMap、filter、mapParitions、union
它们只是将Parition的数据根据规则进行转化,并不做其它处理
只是将数据从一个形式转化成另一种形式
3.2.3 Transfermations 常见的宽依赖
cogroup、join、gourpByKey、reduceByKey、distinct、intersection
对于groupByKey 子RDD所有Partition会依赖于 parent RDD的所有Partition
子RDD的Partition是parent RDD的所有Partition Shuffle的结果
3.2.4 怎么分辨 Narrow Or Wide Dependency
- Narrow dependency objects
OneToOneDependencyPruneDependencyRangeDependency
- Wide denpendency objects
ShuffleDependency
查看RDD依赖关系 option.dependenices
查看RDD生命线 option.toDebugString
3.2.5 DAG的生成
原始的RDD(S)通过一系列转换就形成了DAG
RDD之间的依赖关系包含RDD由哪些 parent RDD(S)转换而来和它依赖parent RDD(S)的哪些partitions
Spark是如何根据DAG来生成计算任务呢?
- 根据依赖关系的不同将DAG划分成为不同的阶段(Stage)
- 对于窄依赖
- Partition关系很明确的,可以在一个线程中完成,它被 Spark划分到同一个执行阶段
- 对于宽依赖(spark划分Stage的依据)
- 由于Shuffle的存在,只有在RDD(S)Shuffle处理完成后,才可以执行接下来的计算
- 在一个Sate内部,每个Partition都会被分配一个计算任务(Task),可并行。
- State之间的根据依赖变成一个大粒度的DAG,这个DAG的执行顺序从前向后
- State只有在它没有parent State 或者parent Stage都已经执行完后,才可以执行。
3.2.6 RDD 的容错机制
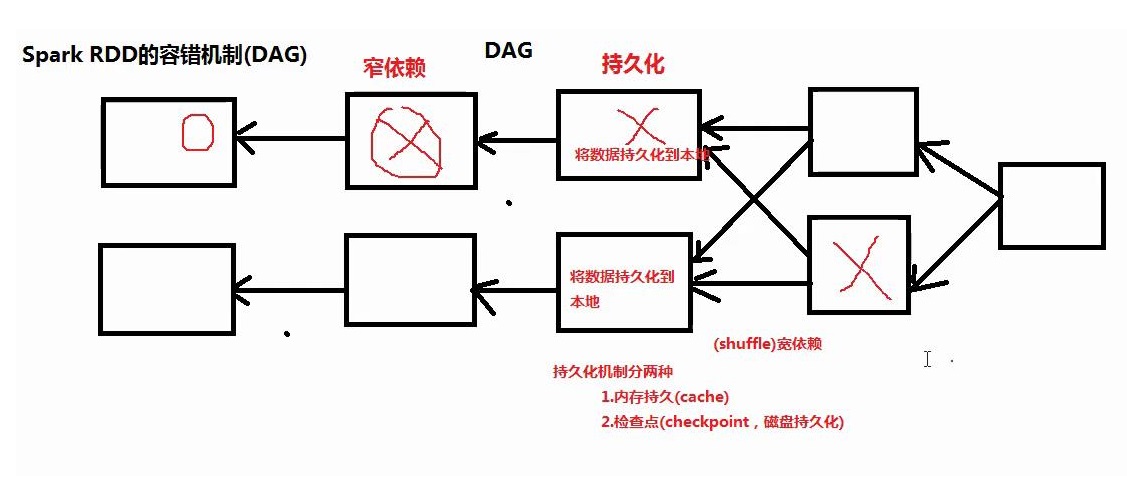
如果某个RDD计算错误,子RDD则找其父RDD,重新计算该RDD,如果此时是宽依赖,则会对集群性能造成很大影响。
此时解决的办法,是将数据持久化。
持久化两种机制:
- 内存持久(cache)
- 检查点(Checkpoint, 磁盘持久化)
4 RDD的计算
4.1 Task简介
- 原始RDD经过一系列转换后,会在最后一个RDD上触发上一个任务,这个动作会成一个job
- Job会被分成一批计算任务task,这批task会被提交到集群上的Executor节点去计算
- Executor在准备好RDD环境后,会通过调用
org.apache.spark.scheduler.MapTask#run来执行计算
Spark的Task分两种:
org.apache.spark.scheduler.ShuffleMapTaskorg.apache.spark.scheduler.ResultTask
DAG的最后一个阶段会为每个结果和Partition生成一个ResultTask,其余所有阶段都会生成ShuffleMapTask。生成的Task会被发送到已经启动的Executor上,由Executor来完成计算任务。
4.2 Task执行起点
org.apache.spark.scheduler.Task#run 会调用ShuffleMapTask或者ResultTask的runTask;runTask则会调用RDD的org.apache.spark.rdd.RDD#iterator
package org.apache.spark.rdd.RDD
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
//如果存储级别不是None,那么先检查是否有缓存;没有则开始计算
SparkEnv.get.cacheManager.getOrCompute(this, split, context, storageLevel)
} else {
computeOrReadCheckpoint(split, context)
}
}
在运行时节点所需要的环境信息SparkEnv中, cache-Manager是org.apache.spark.CacheManager, 它负责调用CacheManager来管理RDD缓存,缓存过的RDD接下的运算都可以通过BlockManager来直接读取缓存后返回。
4.3 缓存的处理
- cacheManager会通过RDD的ID和当前计算Partition的ID向Storages模块的BlockManager发送请求,
- 如果获取到Block信息则直接返回。
- 否则,代表该RDD是需要计算的。这个RDD可能是被计算过并被存储到内存中,但是后来内存紧张,这部分被清理了。
- 计算结束后,会根据用户定义存储级别,写入BlockManager中。下次计算就可以不经过计算直接读取RDD,提高性能。
package org.apache.spark.CacheManager#getOrCompute
def getOrCompute[T](
rdd: RDD[T],
partition: Partition,
context: TaskContext,
storageLevel: StorageLevel): Iterator[T] = {
val key = RDDBlockId(rdd.id, partition.index)
logDebug(s"Looking for partition $key")
blockManager.get(key) match { //向blockManager块中是否有缓存
case Some(blockResult) => //缓存命中
// 更新统计信息, 将缓存作为结果返回
val inputMetrics = blockResult.inputMetrics
val existingMetrics = context.taskMetrics
.getInputMetricsForReadMethod(inputMetrics.readMethod)
existingMetrics.incBytesRead(inputMetrics.bytesRead)
val iter = blockResult.data.asInstanceOf[Iterator[T]]
new InterruptibleIterator[T](context, iter) {
override def next(): T = {
existingMetrics.incRecordsRead(1)
delegate.next()
}
}
case None => // 没有缓存命中,则需要计算
// 加载分区需要获得锁,如果在其它的线程,正持有该锁,则等待它结束,释放该锁。
// 判断当前是否有线程正在处理当前的Partition, 如果有则等待它结束后,直接从BlockManage
// 中读取处理结果,如果没有,则storedValues为None。
val storedValues = acquireLockForPartition[T](key)
if (storedValues.isDefined) { //已经被其它线程处理
return new InterruptibleIterator[T](context, storedValues.get)
}
// 需要加载自己的分区,即需要计算
try {
// 如果在checkpoint中存在数据,则直接读取。否则调用rdd的compute()开始计算
val computedValues = rdd.computeOrReadCheckpoint(partition, context)
// 如果数据在本地(Driver端),则不要缓存结果。这个主要是为了first, take
// 这类任务没有shuffle阶段,直接运行在Driver端可能更省时间。
if (context.isRunningLocally) {
return computedValues
}
// 将计算机结果写入到BlockManager
val updatedBlocks = new ArrayBuffer[(BlockId, BlockStatus)]
val cachedValues = putInBlockManager(key, computedValues, storageLevel, updatedBlocks)
// 更新任务的统计信息
val metrics = context.taskMetrics
val lastUpdatedBlocks = metrics.updatedBlocks.getOrElse(Seq[(BlockId, BlockStatus)]())
metrics.updatedBlocks = Some(lastUpdatedBlocks ++ updatedBlocks.toSeq)
new InterruptibleIterator(context, cachedValues)
} finally {
loading.synchronized {
loading.remove(key)
// 如果有其它任务正在等待该Partition的处理结果,那么通知它们
// 结果已经存在BlockManager中(释放锁)
// (注意:前面的类不会写入到BlockManager的本地任务)
loading.notifyAll()
}
}
}
}
4.4 checkpoint的处理
如果缓存没有命中,首先会判断是否保存了RDD的Checkpoint,如果有则读取Checkpoint。
那么checkpoint的数据是如何写入的呢?
- 在job结束后,会判断是否需要checkpoint。
- 如果需要就调用
org.apache.spark.rdd.RDDCheckpointData#doCheckpoint doCheckpoint首先会创建一个文件目录- 然后,启动一个job来计算,并将计算结果写入新建的目录
- 接着创建一个
org.apache.spark.rdd.CheckpointRDD - 原始RDD的所有依赖被清除。RDD转换计算链(compute chain)等信息被全部清除。
核心逻辑
package org.apache.spark.rdd.RDDCheckpointData
// 创建一个保存checkpoint数据的目录
val path = new Path(rdd.context.checkpointDir.get, "rdd-" + rdd.id)
val fs = path.getFileSystem(rdd.context.hadoopConfiguration)
if (!fs.mkdirs(path)) {
throw new SparkException("Failed to create checkpoint path " + path)
}
// 创建广播变量
val broadcastedConf = rdd.context.broadcast(
new SerializableWritable(rdd.context.hadoopConfiguration))
// 开始一个新的job进行计算,计算结果存入path路径
rdd.context.runJob(rdd, CheckpointRDD.writeToFile[T](path.toString, broadcastedConf) _)
val newRDD = new CheckpointRDD[T](rdd.context, path.toString)
// 保存结果,清除原始RDD的依赖、Partition信息等
RDDCheckpointData.synchronized {
cpFile = Some(path.toString)
cpRDD = Some(newRDD) //RDDCheckpointData对应的ChecpointRDD
// 底层调用的clearDependencies()
rdd.markCheckpointed(newRDD) // 清除原始的依赖、parition
cpState = Checkpointed //mark checkpoint的状态为完成
}
清除了RDD的依赖后,并没有和CheckpointRDD建立联系。Spark是如何确定一个RDD是否被Checkpoint了,d而且正确读取checkpoint的数据呢?
- 在
org.apache.spark.rdd.RDD#dependencies的实现,它会首先判断当前的RDD是否已经被Checkpoint过了,如果有,那么RDD的依赖就变成了对应的CheckpointRDD:
/** An Option holding our checkpoint RDD, if we are checkpointed */
private def checkpointRDD: Option[RDD[T]] = checkpointData.flatMap(_.checkpointRDD)
final def dependencies: Seq[Dependency[_]] = {
checkpointRDD.map(r => List(new OneToOneDependency(r))).getOrElse {
if (dependencies_ == null) { // 没有checkpoint
dependencies_ = getDependencies
}
dependencies_
}
}
在上述中,有两个地方调用了computeOrReadCheckpoint
org.apache.spark.rdd.RDD#iteratororg.apache.spark.CacheManager#getOrCompute
computeOrReadCheckpoint主要是检查当前RDD是否被checkpoint是否过,有则直接读取Checkpoint中的数据否则开始计算
private[spark] def computeOrReadCheckpoint(split: Partition, context: TaskContext): Iterator[T] =
{
if (isCheckpointed) firstParent[T].iterator(split, context) else compute(split, context)
}
firstParent[T].iterator(split, context) 最终都会调用它的compute
// org.apache.spark.rdd.CheckpointRDD#compute
override def compute(split: Partition, context: TaskContext): Iterator[T] = {
val file = new Path(checkpointPath, CheckpointRDD.splitIdToFile(split.index))
CheckpointRDD.readFromFile(file, broadcastedConf, context) //读取checkpoint的数据
}
4.5 RDD计算逻辑
RDD的计算逻辑在org.apache.spark.rdd.RDD#compute中实现。每个特定的RDD都会实现compute
package org.apache.spark.rdd.RDD#compute
def compute(split: Partition, context: TaskContext): Iterator[T]
5 Understanding closures (理解闭包函数)
var counter = 0
val data = Array(1, 2, 3, 4, 5, 6)
var rdd = sc.parallelize(data)
// Wrong: Don't do this!!
rdd.foreach(x => counter += x)
// 此时输出的结果为0
println("Counter value: " + counter)

-
每一个RDD操作会在Executor中初始化成一个Task任务。
- 发送到集群中每个Executor 的是
counter的副本,而不是Driver Program 中的var counter = 0 - 每个Executor中任有
counter进行计算,但这些操作对Driver Program 来说不存在。 - 所以最终输出
counter的结果为0
此时,可以用全局变量解决该问题:
val accum = sc.accumulator(0, "My Accumulator")
sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
accum.value
5 Shuffle operations
- Shuffle 是什么
不同节点之间的数据传输
- Shuffle的缺点
在Spark中的某些RDD操作,会触发Shuffle事件。
Shuffle事件一旦产生,就把我们所操作的数据集进行重新分布。
一旦涉及到重新分布,将会耗费大量的IO与网路资源。
ReduceByKey 生产中会遇到的问题
- 需求:
第一列:代表游客的编号 第二列:代表游客旅行地 第三列:代表游客旅行的消费 //统计出每一个用户本月旅行次数以及总消费 (100,2,300)
- 代码如下:
val arr2 = Array(
(100,"Geneva",22.25),
(100,"Zurich",42.10),
(200,"Fribourg",12.40),
(200,"St.Gallen",8.20),
(300,"Lucerne",31.60),
(300,"Basel",16.20)
)
val rdd = sc.parallelize(arr2)
println("次数:" + groupByKeyRDD.count)
groupByKeyRDD.foreach(x => {
println("ID: " + x._1)
println("总额:" + x._2.sum)
})
此时就会产生Shuffer:
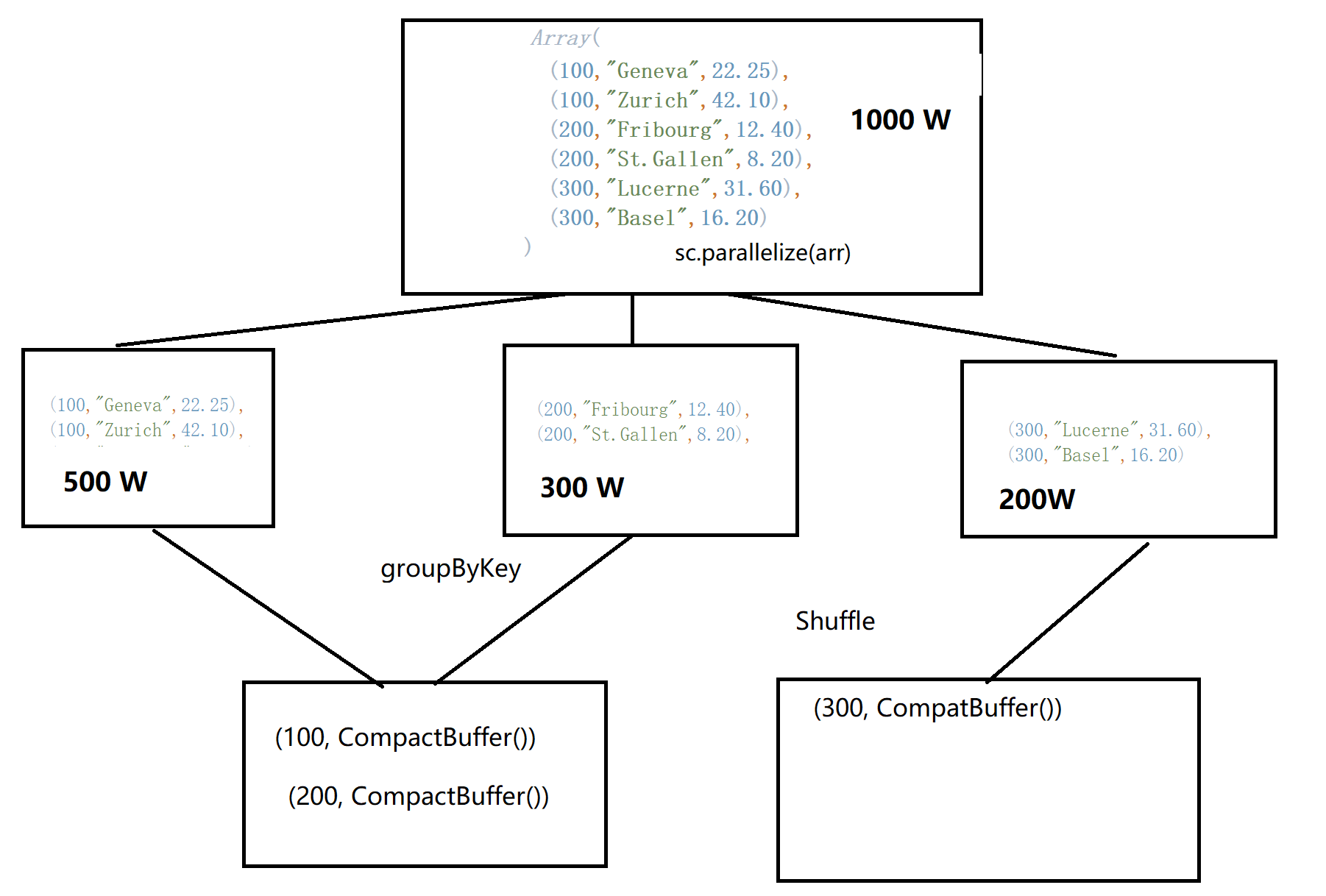
在进行Shuffle操作前,尽可能的减少每个分区即将进行Shuffle的数据量。(优化技巧)
- 数据倾斜。
我现在有上亿条的数据需要进行分组求和、求平均,该如何操作?为什么?
解决方案就是,在执行Shuffle前,尽可能的减少需要交换的数据。
减少Shuffle数据的两种方案?
选择具有Combiner函数的RDD操作(reduceByKey)
对业务数据进行数据变换.
(100,"xxxx",2500) (100,(1,2500)) (2500,(1,100))
Shuffle 优化主要目的:
- 数据处理(例如:reduceByKey 本地shuffle提速)
- RDD容错计算(提速)
6 Spark 经验之谈
如果面对比较复杂数据分析时,通常会将数据转成Tuple
Tuple操作的好处: 列式操作
("class1", 85)
("class1", 100)
("class2", 85)
("class2", 100)


