Spark核心源码分析
Spark源码分析
1.spark-shell底层执行过程
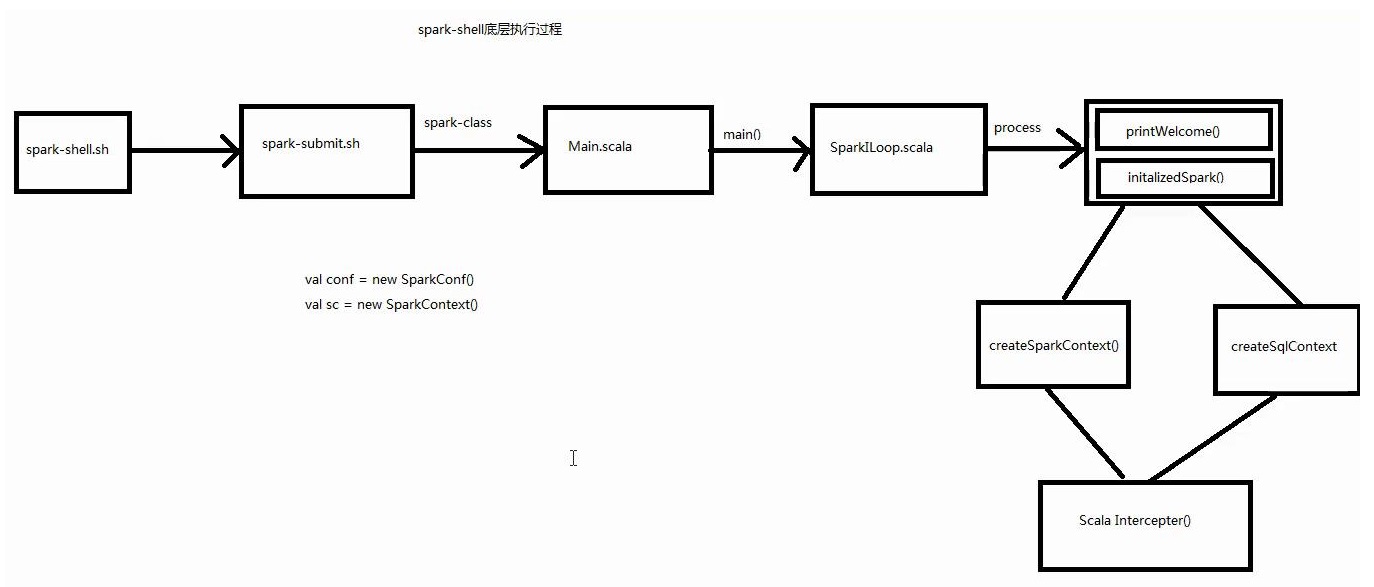
-
spark-shell.sh。 底层调用的是spark-submit 调用的是org.apache.spark.repl.Mainfunction main() { if $cygwin; then stty -icanon min 1 -echo > /dev/null 2>&1 export SPARK_SUBMIT_OPTS="$SPARK_SUBMIT_OPTS -Djline.terminal=unix" "${SPARK_HOME}"/bin/spark-submit --class org.apache.spark.repl.Main --name "Spark shell" "$@" stty icanon echo > /dev/null 2>&1 else export SPARK_SUBMIT_OPTS "${SPARK_HOME}"/bin/spark-submit --class org.apache.spark.repl.Main --name "Spark shell" "$@" fi } -
Main.scala//Main.scala object Main { //声明一个interp类型为SparkILoop private var _interp: SparkILoop = _ def interp = _interp def interp_=(i: SparkILoop) { _interp = i } def main(args: Array[String]) { _interp = new SparkILoop // 调用process方法 _interp.process(args) } } -
SparkLoop.scala 。 主要用于
createSparkContext以及createSqlContext// SparkLoop.scala def process(args: Array[String]): Boolean = { neededHelp() match { // 将一些配置信息传入process case "" => command.ok && process(command.settings) case help => echoNoNL(help) ; true } } // process的核心代码 private def process(settings: Settings): Boolean = savingContextLoader { // 创建一个Interpreter对象 createInterpreter() // 打印一些spark输出信息 addThunk(printWelcome()) // 初始化Spark // org.apache.spark.repl.Main.interp.createSparkContext() // org.apache.spark.repl.Main.interp.createSQLContext() addThunk(initializeSpark()) // spark-shell 开始循环读取 命令行输入 try loop() catch AbstractOrMissingHandler() finally closeInterpreter() } // Constructs a new interpreter. protected def createInterpreter():unit{ // intp是一个全局变量 返回SparkILoopInterpreter对象 intp = new SparkILoopInterpreter }
2.Spark集群中Master的底层执行过程
sbin/start-all.sh sbin/start-Master.sh Master sbin/Start-Slave.sh Worker
3.Spark集群中Worker的底层执行过程
4.通过Spark-submit.sh提交jar到Spark Master的执行过程。
1.spark-submit.sh
5.TaskScheduler的任务调度
6.DAG中的stage任务划分 7.job任务触发。 8.BlockManager 9.CacheManager


