HDFS上传和下载简述流程
客户端上传数据:
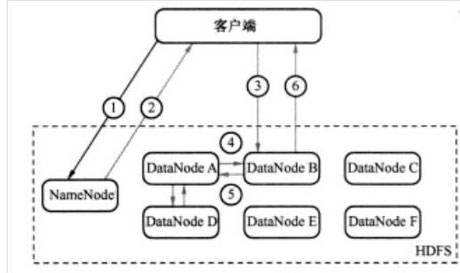
客户端与NameNode通迅
- 客户端上传一个文件,namenode请求上传文件。
- namenode响应并获取文件名,从元数据中查找/hadoop/hdfs/中是否已经存在相同文件名的文件,如果不存在则允许上传
- 客户端根据配置(dfs.blocksize - 块大少、hadoop 2.x 默认为128M)将文件切成N个block。
- 客户端向nameNode发出RPC请求上传第一个block,nameNode返回dataNode列表(dfs.replication - 副本个数、默认为3,需要多少个副本则返回多少个dataNode,选择dataNode主要考虑空间与距离)。
客户端与DataNode通迅
- Client与DataNodeA建立通道,上传第一个Block
- 请求建立block传输通道channel
-
DataNodeA向DataNodeB建立通道 , 通过PIPE LINE将数据传输至dataNodeB。
-
DataNodeB与dataNodeC建立通道,通过PIPE LINE将数据传输至dataNodeC。
-
- 客户端与dataNodeA传输完毕,dataNodeA则返回一个成功答应。
MOST IMPORT
- 数据传输是以packet为单位进行传输,大小默认为64K。
- packet以chunk为单位进行校验,大小默认为512Byte。
- 只要有一个副本上传成功即可,其余失败的副本,之后nameNode会做异步的同步。
- 每传一个block,都需要向nameNode发出请求, 再分配客户端复本个数的datanode。
客户端读数据:
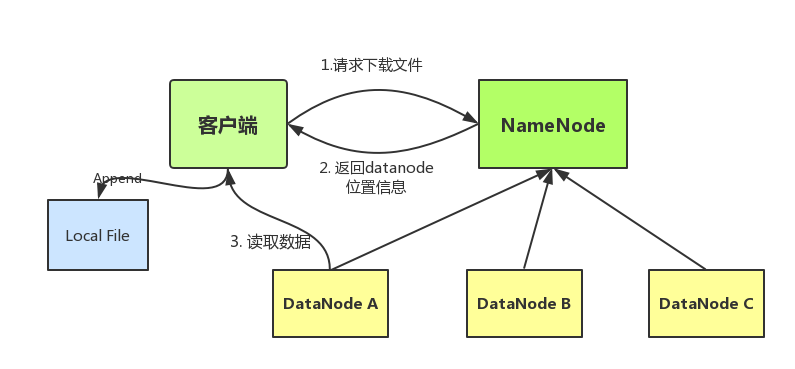
读文件流程:
- 应用程序通过HDFS客户端向NameNode发生远程调用请求。
- NameNode收到请求之后,返回文件的块列表信息。块列表信息中包含每个block拷贝的datanode地址。
- HDFS 客户端会选择离自己最近的那个拷贝所在的datanode来读取数据。
- 数据读取完成以后,HDFS客户端关闭与当前的datanode的链接。
参考:

