Hadoop权威指南
1 Hadoop
Hadoop可以看做将MapReduce计算转移到存储有部分数据的各台机器上。
三大设计目标:
- 为只需要几分钟或几小时就能完成的任务提供服务。
- 运用于同一个内部有高速网络连接的数据中心内。
- 数据中心内的计算机都是可靠的、专门的硬件
1.1 普通分析
并行处理程序进行数据分析:
- 将任务划分成大小相同的作业。
- 合并各个独立进程的运行结果,可能还需要进行额外处理。
- 受限单台计算机的处理能力。
1.2 使用Hadoop来分析数据
MapReduce任务过程分两个阶段:都以键-值对做为输入和输出
- map阶段:数据准备
- 提取想要的字段,以及去除已损数据;
- 输入的是NCDC原始数据。默认为文本格式
- 键(key)是文件中的行偏移量,值(value)为文本格式的数据
- reduce阶段:数据处理
- 比如:这个处理基于键-值对进行排序和分组
Unix管线模拟整个MapReduce的逻辑数据流
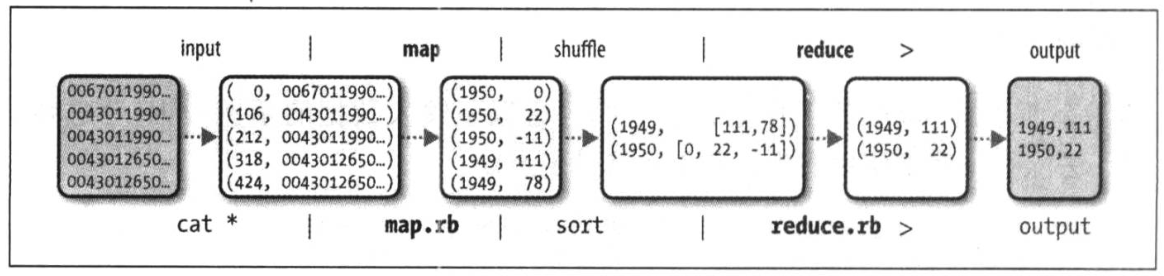
hadoop将作业分成若干个任务(task)来执行:
- map任务
- reduce任务
由YARN进行调度,第一个分片都会构建一个map任务
一个Reduce任务的MapReduce数据流:
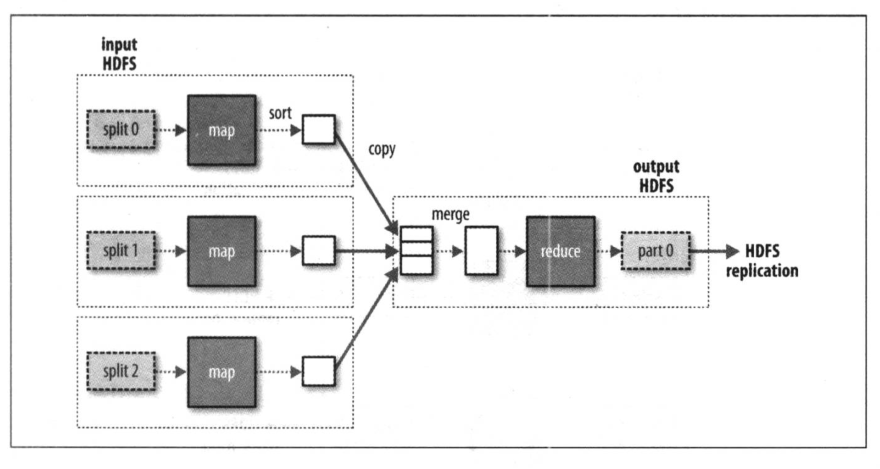
如果有多个map任务就会针对输出进行分区(partintion),即为每一个reduce任务建一个分区
多个任务的数据流图:shuffle
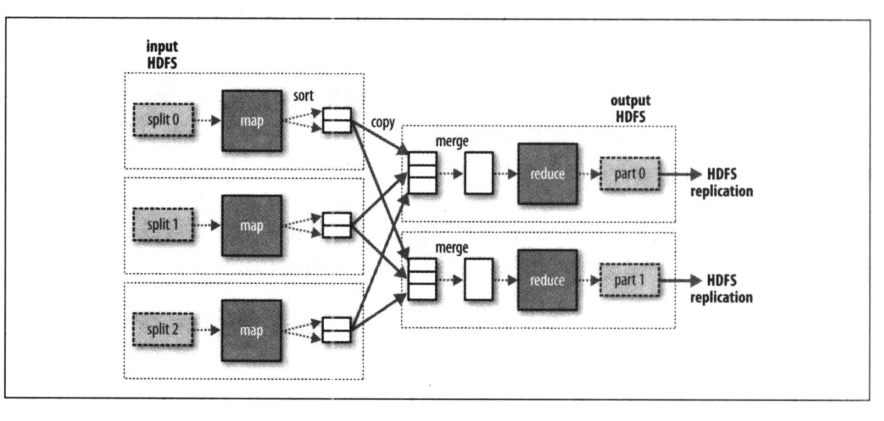
数据处理可以完全并行(无需混洗)
combiner函数
可以针对map任务的输出指定一个 combiner ,combiner 函数的输出作为reduce 函数的输入。
2 HDFS
HDFS是Hadoop的文件系统,实际上Hadoop是一个综合性的文件系统抽象。
2.1 数据块
HDFS块(block)默认为128M(以前的版本默认是64M)。与面向单一磁盘文件不同的是,HDFS中小于一个块大小的文件不会占据整个空间。
HDFS的块比磁盘的块大,目的是为了最小化寻址开销。
优点:
- 文件大小可以大于网络中任意一个磁盘容量
- 使用抽象块而非整个文件作为存储单元,简化了存储子系统的设计
- 适合用于数据备份
2.2 namenode和datanode
客户端(client):代表用户通过与namenode和datanode交互访问整个文件系统。
2.2.1 namenode (管理节点)
管理着整个HDFS文件系统的元数据。记录每个文件中各个块所在的数据节点信息,它并不永久保存块的位置信息,因为这些信息会在系统启动时根据数据节点信息重建。
- 初始化:
- 生成fsimage 和 blockpool 编号
- 启动:
- 把残留的edits和fsiamge合并
- datanode向namenode进行汇报(安全模式),元数据的校验,验证datanode是否正常启动之后 ,datanode会和namenode保持心跳的交换。 默认保持10S的心中信息
元数据大概分两个层次:
- Namespace管理层,负责管理文件系统中的树状目录结构以及文件与数据块的映射关系
- Namespace管理的元数据除内存常驻外,也会周期Flush到持久化设备上FsImage文件
- BolcksMap块管理层,负责管理文件系统中文件的物理块与实际存储位置的映射关系。
- BlocksMap元数据只在内存中存在
当NameNode发生重启,首先从持久化设备中读取FsImage构建Namespace,之后根据DataNode的汇报信息重新构造BlocksMap。
HDFS对namenode两种容错机制:
- 备份那些组成文件系统元数据持久状态的文件。Hadoop可以通过配置使namenode在多个文件系统上保存元数据的持久状态。
- 辅助的namenode(Second NameNode),但它不能作namenode。它会定期合并编辑日志(edits log)与命名空间镜像(fsimage),以防止日志过大。这个辅助namenode一般会在另一台单独的物理计算机上运行,因为它需要占用大量CPU时间,并且需要与namenode一样多的内存来执行合并操作。但是,辅助namenode保存的状态滞后于主节点,所以在主节点全部失效时,难免会丢失部分数据。
namenode安全模式(safenode)
- namenode在刚启动时,内存中只有文件和文件的块id及副本数量,不知道datanode在哪里。
- namenode需要等待所有datanode向他汇报自身持有的块信息,namenode才能在元数据中补全文件块信息中的位置信息。
- 只有当namenode长到99.8%的块位置信息,才会即出安全模式,正常对外提供服务。
2.2.2 datanode (工作节点)
是文件系统的工作节点。它们根据需要存储并检索数据块(受客户端或namenode调试),并定期向namenode发送它们所存储的块的列表。
datanode为什么要定期汇报自身block信息:
- 当集群中某些副本失效时,集群如何恢复block初始副本数量的问题。
datanode上保存文件,是以block的形式保存。block默认大小为128M。块的大小根据上传文件的大小/block的大小。
data保存时,会有一个副本机制,默认是会为每个文件保存3份(dfs.replication)。
block的分配原则(网络距离越近,优先程度越高):
- 和客户端在同一个机架的节点
- 和客户端在不同机架的节点
- 和客户端在同一个机架的其他一个节点
- 负载均衡
datanode故障无法与namenode通信:
- namenode不会立即判断datanode死亡,要经过一段时间,这段时间称作超时时长。
datanode为什么要用block的形式来存放数据?
- 大文件存放无压力
- 高可用
- blocke有规律的存储和读取
鉴于block保存机制,使用hdfs来存放文件的时候,需要注意些什么?
- hdfs更适合放大文件。
- 3ktxt,block形式存放,占用空间是依然是3k,但是会占用一个block。
hdfs dfsadmin -report :可以通过此命令查看块信息
2.3 HDFS高可用
默认没有高可用机制。可以通过配置实现。
活动-备用(active-standby)namenode。当活动namenode失效,备用namenode就会接管它的任务,并开始服务于客户端的请求,不会有任务明显中断。
- namenode之间需要通过高可以用共享存储编辑日志的共享。
- datanode需要同时向两个namenode发送数据块处理报告。数据块的映射信息存储在namenode的内存中。
- 辅助namenode的角色被备用namenode所包含,备用namenode为活动namenode命名空间设置周期性检查点。
2.3.1 故障切换与规避
- 故障转移控制器(failover controller): 管理将活动的namenode转移为备用namenode的转换过程。
- 默认使用ZooKeeper来确保有且仅有一个活动namenode。
- 第一个namenode运行着一个轻量级的故障转移控制器,监视宿主机namenode是否失效,并在namenode失效时进行故障切换。
-
平稳故障转移(graceful failover): 故障转移器可以组织两个namenode有序地切换。
- 规避(fencing): 以确保先前活动的namenode不会执行危害系统并导致系统崩溃的操作。
2.4 命令行接口
-
fs.defaultFS, 设置为 hdfs://localhost/,用于设置hadoop的默认文件系统。HDFS的守护程序通过该属性来确定HDFS namenode的主机和端口。
-
fs.replication, HDFS默认设置将文件系统的复本。设为1时,单独一个datanode上运行,HDFS将无法复制到3个datanode。设置为5时,如果节点只有3个,它还是只会复制为3份。
2.4.1 文件系统的基本操作
上传文件
bin/hadoop fs -put tmp.txt hdfs://hadoop1:9001/
下载文件
bin/hadoop fs -get hdfs://hadoop1:9001/tmp.txt
从本地将一个文件复制到HDFS:
默认域名在core-site.xml中的defaultFS指定
bin/hadoop fs -copyFromLocal input/core-site.xml hdfs://hadoop1/user/root/core.xml
省略, hdfs://hadoop1,因为该项在core-site.xml指定。
bin/hadoop fs -copyFromLocal input/core-site.xml /user/root/core.xml
相对路径(默认为/user/root)
bin/hadoop fs -copyFromLocal input/core-site.xml core.xml
将文件复制回本地,并查检是否一致
bin/hadoop fs -copyToLocal core.xml input/core-site.copy.xml
md5sum input/core-site.copy.xml input/core-site.xml
新建一个目录:
bin/hadoop fs -mkdir books
默认在/user/root(用户)目录下
显示/user/root下的目录结构
hadoop fs -ls .
2.4.2 HDFS权限
启动权限 dfs.permissions.enabled属性
超级用户是namenode进程的标识。对于超级用户,系统不会执行任何检查。
3 数据流
3.1 文件读取(JAVA API式)
HDFS、namenode、datanode之间的数据流交互:
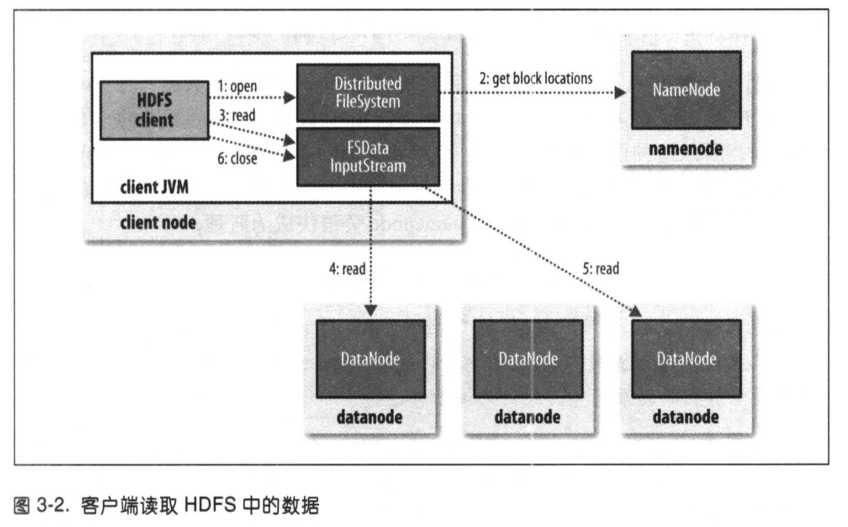
- client通过
FileSystem对象(对于hdfs,DistributedFileSystem)的open()方法打开文件。 DistributedFileSystem通过远程调用(RPC)来调用namenode,确定文件起始块的位置。对于每一个块, namenode返回该块副本的datanode地址。datanode根据与client的距离来排序。- 对
DistributedFileSystem类返回的FSDataInputStream(文件定位输入流)类,调用read()方法。根据namenode返回的该块datanode地址,链接最近的文件中第一个块所在的datanode。 - 反复调用
read()方法,可以将数据从datanode传输到客户端 - 到达块的末端时,
DFSInputStream(FSDataInputStream类封装的对象)关闭与datanode的链接,然后寻找下一个块的最佳datanode。 - client客户端读取完成,FSDataInputStream调用close()方法
如果DFSInputStream在与datanode通迅时遇到错误,会尝试从这个块的另外一个邻近datanode读取数据。并记住故障的datanode, 保证后续不会反复读取该节点。
客户端可以直接连接到datanode检索数据,且 namenode告知client每个块所在最佳的datanode。namenode只需响应位置的请求,而无需响应数据请求。
3.2 网络拓扑与Hadoop
带宽依次递减:
- 同一节点上的进程
- 同一机架上的不同节点
- 同一数据中心不同机架上的节点
- 不同数据中心中的节点
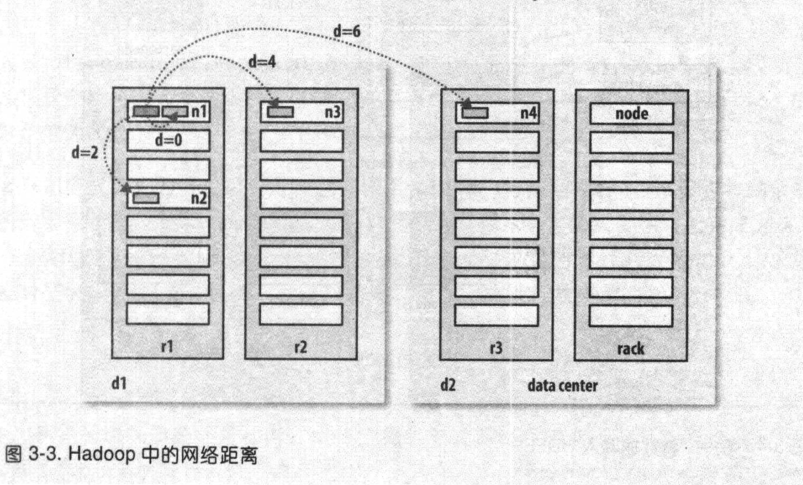
例如, 假设有数据中心d1机架r1中的节点n1。该节点可以表示为/d1/r1/n1。上述四种距离描述:
- distance(/d1/r1/n1, d1/r1/n1)=0
- distance(/d1/r1/n1, d1/r1/d1)=2
- distance(/d1/r1/n1, d1/r1/d1)=4
- distance(/d1/r1/n1, d1/r1/d1)=6
文件写入
如果新建一个文件,把数据写入,最后关闭该文件。
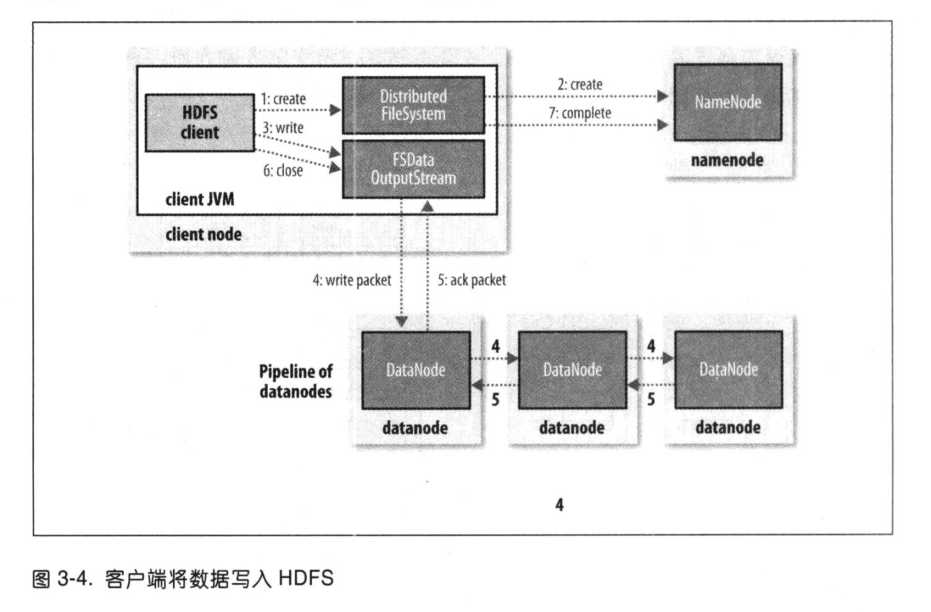
- client通过对
DistributedFileSystem对象调用reate()来新建文件 DistributedFileSystem对namenode创建一个RPC调用,在文件系统的命名空间中新建一个文件,此时文件还没有相应的数据块- namenode执行各种不同的检查以确保这个文件不存在以及client新建该文件的权限。
- 如果检查通过,namenode就会创建新文件并记录;否则,文件创建失败并向client抛出IOException异常。
DistributedFileSystem向客户端返回一个FSDataOutputStream对象- 由此 client 开始写入数据。
- 类似读取事件,
FSDataOutputStream封装一个DFSoutPutStream对象,该对象负责 datanode 与 namenoe之间的通信。
在client写入时,DFSOutputStream将它分成一个个数据包,并写入内部队列,称为“数据队列” (data queue)。DataStreamer 处理数据队列,它的责任是挑选出适合存储数据复本一组datanode,并据此来要求namenode分配新的数据块。
- 这一组datanode构成一个管线。
- 假设复本为3,所以管线中有3个节点。
DataStreame将数据包流式传输到管线中第1个datanode,该datanode存储数据包并将它发送到第2个datanode,同样第2个datanode存储该数据包并将它发送到第3个datanode。
DFSOutputStream也维护着一个内部数据包队列来等待datanode的收到确定回执,称为“确认队列”(ack queue)。收到管道中所有的datanode确认信息后,该数据包才会被确认队列删除。
如果任何datanode在数据写入期间发生故障,则执行以下操作(对写入数据client透明)。
-
首先关闭管线,确认把队列中的所有数据包都添加回数据队列的最前端,以确保故障节点下游的datanode不会漏掉任何一个数据包。
- 为存储在另一正常datanode的当前数据块指定一个新的标识,并将该标识传送给namenode,以便故障datanode在恢复后可以删除存储部分数据块。
- 从管线中删除故障datanode, 基于两个正常datanode构建一条新管线。余下数据写入管线中正常datanode。namenode注意到复本不足时,会在另一个节点上创建一个新的复本。
同时不排除多个datanode同时发生故障的可能性。只要写入了dfs.namenode.replication.min的复本(默认为1),写操作就会成功,并这个块可以在集群中异步复制,直到其达到复本数(dfs.replication的默认值 为3)。
- client完成数据的写入后,对数据流调用close()方法。
- 该操作将剩余的所有数据写入datanode管线, 并联系namenode告知其文件写入完成之前,等待确认。namenode已经知道文件由哪些块组成(因为DataStreamer请求分配数据块),所以它在返回成功之前只需等待数据块进行最小量的复制。
复本存放问题
namenode 如何选择在哪个 datanode 存放复本:
- 在运行客户端的节点上放第 1 个复本(如果客户端在集群外,就随机选择一个节点,系统会负载均衡)
- 第2 个复本放在与第一个不同且随机另外选择的机架中节点上(离架)
- 第 3 个复本放在与第2个复本同一个机架上, 且随机选择加一个节点。
- 其他复本放在集群中随机节点上, 系统会尽量避免在同一个机架上放太多复本。
一旦选定复本的放置位置,就根据网络拓扑结构创建一根管线。假设复本数为3。
参考:
